[論文レビュー] Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexionは、環境フィードバックに基づく口頭の内省を生成することにより、試行錯誤から言語エージェントが学習できるようにし、それをエピソード記憶に保存して将来の試行を導く。ウェイトの更新なしで、コーディング、推論、意思決定のベンチマークで最先端の結果を達成する。
Large language models (LLMs) have been increasingly used to interact with external environments (e.g., games, compilers, APIs) as goal-driven agents. However, it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive model fine-tuning. We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback. Concretely, Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials. Reflexion is flexible enough to incorporate various types (scalar values or free-form language) and sources (external or internally simulated) of feedback signals, and obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). For example, Reflexion achieves a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4 that achieves 80%. We also conduct ablation and analysis studies using different feedback signals, feedback incorporation methods, and agent types, and provide insights into how they affect performance.
研究の動機と目的
- 重み更新ではなく口頭のフィードバックを活用する、従来のRLの軽量な代替案を動機づける。
- 自己内省とエピソード記憶が、意思決定・推論・プログラミングタスク全体でタスクパフォーマンスを改善することを示す。
- 複数の環境と言語にまたがるスケーラビリティを示す。新しいLeetcodeHardGymベンチマークを含む。
- フィードバックのタイプと記憶が性能に与える影響を理解するためのアブレーションを提供する。
提案手法
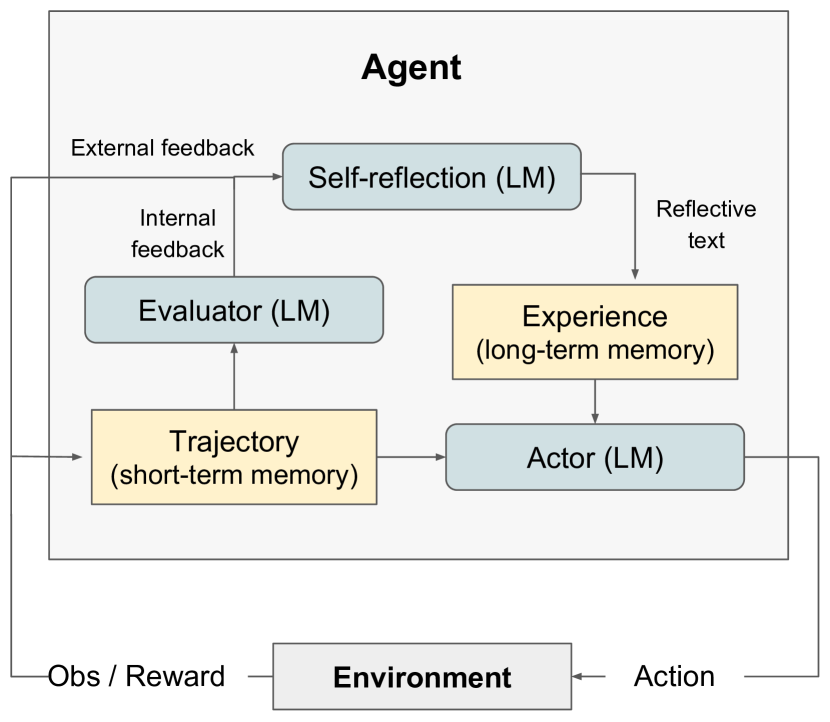
- テキストと行動の生成を行うLLMベースのActor、Actorの出力を評価するEvaluator、記憶を補強する口頭フィードバックを生成するSelf-Reflectionの3モデルからなるモジュラーなReflexionフレームワークを提案する。
- 環境フィードバックを口頭の内省に変換し、それを記憶バッファに保存して将来のエピソードに影響を与える。
- 短期的(トラジェクトリ)記憶と長期的(自己内省)記憶を用いてActorの決定を条件付ける。
- さまざまなフィードバック信号(バイナリ、ヒューリスティック、自己評価)と異なるタスクタイプ(意思決定、推論、プログラミング)を用いた実験。
- Reflexionアルゴリズムを、各試行がトラジェクトリ、Evaluatorスコア、および将来の試行のためにメモリへ追加される自己内省を生み出す反復ループとして説明する。

実験結果
リサーチクエスチョン
- RQ1言語自己内省とエピソード記憶が、勾配ベースの微調整なしに、スパースな試行錯誤フィードバックからLLMベースのエージェントが学習できるか。
- RQ2異なるフィードバック信号と記憶構成が、意思決定・推論・プログラミングタスクでの性能にどのように影響するか。
- RQ3確立されたベンチマークと新しいコード生成環境におけるReflexionの利点は何か。
- RQ4プログラミングタスクにおいて言語とツールの使用に対してReflexionは頑健か。
主な発見
| ベンチマーク + 言語 | 従来のSOTA Pass@1 | SOTA Pass@1 | Reflexion Pass@1 |
|---|---|---|---|
| HumanEval (PY) | 65.8 (CodeT+GPT-3.5) | 80.1 (GPT-4) | 91.0 |
| HumanEval (RS) | – | 60.0 (GPT-4) | 68.0 |
| MBPP (PY) | 67.7 (CodeT+Codex) | 80.1 (GPT-4) | 77.1 |
| MBPP (RS) | – | 70.9 (GPT-4) | 75.4 |
| Leetcode Hard (PY) | – | – | 15.0 |
- Reflexionは、意思決定・推論・プログラミングタスクにおいて、強力なベースラインと比較して性能を向上させる。
- AlfWorldの意思決定では、単純なヒューリスティック自己評価を伴うReflexionがかなりの向上を達成し、12回の試行でほぼ完璧に近い性能に達する。
- HotPotQA推論タスクでは、Reflexionはベースラインを大幅に上回り、CoTおよびReAct系より顕著な改善を示す。
- HumanEvalプログラミング(PythonとRust)では、Reflexionは最先端のpass@1スコアを達成し、特にGPT-4を用いたPython HumanEvalで91.0を示し、従来のSOTAを上回る。
- LeetcodeHardGymは、自己生成のユニットテスト手法で難易度の高いコーディング問題を扱えるReflexionの能力を示し、強力なpass@1結果を達成。
- アブレーション研究は、自己内省と記憶の重要性を示し、いずれかの要素を削除すると性能が低下する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。