[論文レビュー] Reimagining Synthetic Tabular Data Generation through Data-Centric AI: A Comprehensive Benchmark
論文は、統計的忠実性だけでは不十分であることを示し、データ中心のAIフレームワークを用いて合成表形式データの生成を評価・ガイドする。データプロファイルは、複数の生成モデルにおいて下流の有用性を改善する。
Synthetic data serves as an alternative in training machine learning models, particularly when real-world data is limited or inaccessible. However, ensuring that synthetic data mirrors the complex nuances of real-world data is a challenging task. This paper addresses this issue by exploring the potential of integrating data-centric AI techniques which profile the data to guide the synthetic data generation process. Moreover, we shed light on the often ignored consequences of neglecting these data profiles during synthetic data generation -- despite seemingly high statistical fidelity. Subsequently, we propose a novel framework to evaluate the integration of data profiles to guide the creation of more representative synthetic data. In an empirical study, we evaluate the performance of five state-of-the-art models for tabular data generation on eleven distinct tabular datasets. The findings offer critical insights into the successes and limitations of current synthetic data generation techniques. Finally, we provide practical recommendations for integrating data-centric insights into the synthetic data generation process, with a specific focus on classification performance, model selection, and feature selection. This study aims to reevaluate conventional approaches to synthetic data generation and promote the application of data-centric AI techniques in improving the quality and effectiveness of synthetic data.
研究の動機と目的
- 純粋に統計的忠実性だけでは合成表形式データ生成の下流有用性を予測できるか。
- データをプロファイルして合成データ作成をガイドするデータ中心のAIフレームワークを提案する。
- 11データセットにわたり、5つの最先端の表データジェネレータをベンチマークする。
- 下流の分類、モデル選択、特徴選択に対するデータ中心の前処理/後処理の影響を評価する。
- データ中心の洞察を合成データワークフローに統合する実用的な推奨を提供する。
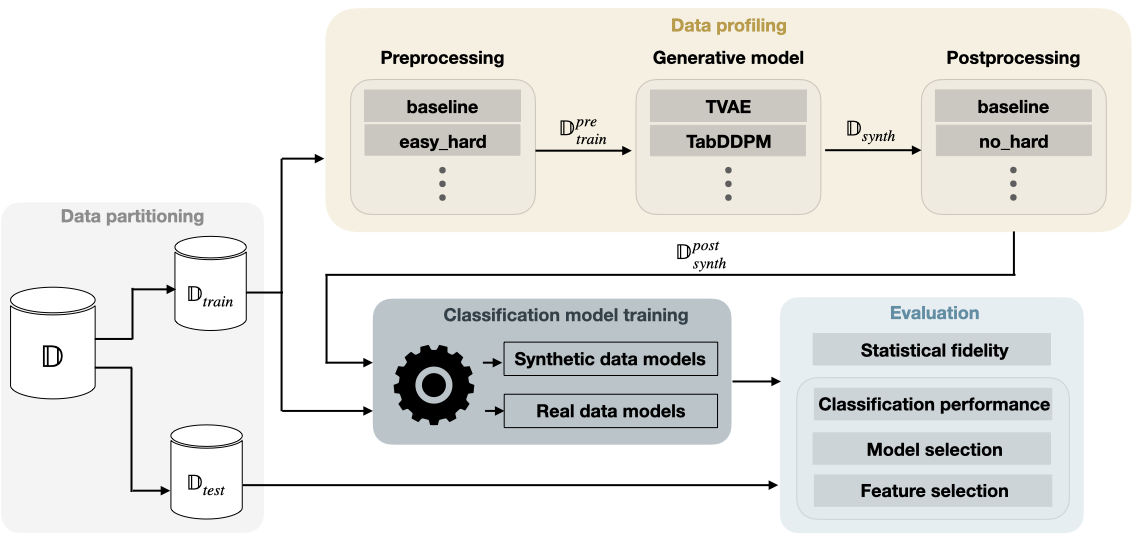
提案手法
- データ中心のプロファイリング(容易/曖昧/難)を、Cleanlab、Data-IQ、Data Mapsなどの方法を用いて定義する。
- ジェネレータモデルの訓練前に実データの前処理を行いプロファイルを作成する。
- 異なるデータプロファイル上で別々の生成モデルを訓練し、合成データを比例的に組み合わせる。
- 合成データに後処理戦略(ベースライン対難例を除去)を適用する。
- 実データと合成データのどちらで分類器を訓練し、下流評価(AUROC、ランキング)で比較する。
- 統計的忠実性を逆KL、MMD、Wassersteinなどの発散測度で評価し、データ有用性タスクへ拡張する。
![Figure 1: Measures of data-centric profiling (A) better reflect the downstream performance of generative models (B) than measures of statistical fidelity (C). Assessed on the Adult dataset [ 16 ] using five different generative models A) Proportion easy examples in the generated datasets identified](https://ar5iv.labs.arxiv.org/html/2310.16981/assets/figs/poc_proportions.png)
実験結果
リサーチクエスチョン
- RQ1統計的忠実性だけで合成表データの下流有用性を予測できるか。
- RQ2データ中心のプロファイリングは分類、モデル選択、特徴選択の現実性と有用性を向上させるか。
- RQ3データプロファイルに導かれた場合、異なる生成モデルは下流タスクでどのように性能が異なるか。
- RQ4ラベルノイズはデータ中心の前処理/後処理の有効性にどのような影響を及ぼすか。
主な発見
| Generative Model | Classification Model | Selection | Feature Selection | Statistical fidelity |
|---|---|---|---|---|
| Real data | 0.866 (0.855, 0.877) | 1.0 | 1.0 | 1.0 |
| bayesian_network | 0.622 (0.588, 0.656) | 0.155 (0.055, 0.264) | 0.091 (-0.001, 0.188) | 0.998 (0.998, 0.999) |
| ctgan | 0.797 (0.769, 0.823) | 0.519 (0.457, 0.579) | 0.63 (0.557, 0.691) | 0.979 (0.967, 0.987) |
| ddpm | 0.813 (0.781, 0.844) | 0.508 (0.446, 0.573) | 0.635 (0.546, 0.718) | 0.846 (0.668, 0.972) |
| nflow | 0.737 (0.713, 0.761) | 0.354 (0.288, 0.427) | 0.415 (0.34, 0.485) | 0.975 (0.968, 0.981) |
| tvae | 0.792 (0.764, 0.818) | 0.506 (0.436, 0.565) | 0.675 (0.63, 0.722) | 0.966 (0.953, 0.978) |
- 統計的忠実性だけでは下流タスクの合成データ有用性を評価するには不十分である。
- 異なる生成モデル(CTGAN、TabDDPM、TVAE)はタスクごとに優れている(モデル選択、特徴選択、分類)。
- データ中心の前処理と後処理は、ほとんどのモデルとデータセットで分類、モデル選択、特徴選択を一般に改善するが、統計的忠実性には時に損失が生じる。
- ラベルノイズが変動する場合でもデータ中心の処理の利益は持続するが、高ノイズ(例:>8%)ではやや低下する。
- 全タスクで支配的な単一ジェネレータはなく、CTGANとTVAEは忠実性と下流有用性の間で有利なトレードオフを提供することが多い。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。