[論文レビュー] Reinforcement and Imitation Learning for Diverse Visuomotor Skills
モデルフリーの深層RL手法で、デモンストレーションと強化学習を組み合わせて、ピクセルから多様なロボット操作タスクのエンドツーエンド視覚運動ポリシーを学習し、sim2real転送性が有望。
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. A brief visual description of this work can be viewed in https://youtu.be/EDl8SQUNjj0
研究の動機と目的
- デモンストレーションを活用して、連続的な視覚運動制御における探索の難易度を低減する。
- 模倣学習を強化学習と統合し、統一されたトレーニングフレームワークを構築する。
- 特権的なシミュレーション情報を活用して学習を安定化・加速させる。
- 一般化とsim2real転送を改善するために、トレーニング条件を多様化する。
- ドメイン乱択化を用いて、実機ロボットへのゼロショット転送の可能性を示す。
提案手法
- GAIL(Generative Adversarial Imitation Learning)からの模倣報酬とタスク報酬を組み合わせたハイブリッド報酬を用いる。
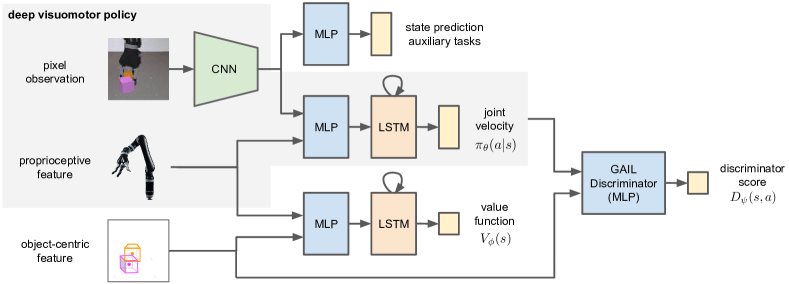
- RGB観測と固有受容感覚特徴を9-DoF関節速度指令へマップするエンドツーエンドの視覚運動ポリシーを学習する。
- (i)デモンストレーション状態からのカリキュラム、(ii)物理状態からの別値学習、(iii)マスキングを用いた対象中心のGAIL識別器、(iv)補助的な状態予測タスクといった特権的なシミュレーション状態を活用する。
- ピクセルにはCNN、固有受容にはMLP、時系列統合にはLSTMコアを用いてポリシーを表現する。
- MuJoCoで多様で手続き的に生成されたオブジェクトとランダム化されたダイナミクスを用いて学習し、sim2realドメイン乱択化を介して実機ロボットへ転送する。
- 識別器が状態軌道を用いるため、デモンストレーションは異なるロボットボディで収集可能とする。

実験結果
リサーチクエスチョン
- RQ1純粋なRLや純粋なILが失敗するような長時間の視覚運動タスクを、ハイブリッドなRLと模倣学習の枠組みで解決できるか。
- RQ2特権的なシミュレーションデータとカリキュラム戦略を活用して学習を安定化させ、収束を加速できるか。
- RQ3対象中心の識別、別個の状態価値学習、補助タスクがポリシー性能に与える影響は何か。
- RQ4シミュレーションで訓練されたポリシーをファインチューニングなしで実機へどの程度転送できるか(ゼロショットsim2real)?
主な発見
- 完全なハイブリッドモデルは6つの操作タスクのすべてを解決し、純粋なRLや純粋なGAILのベースラインを上回る。
- デモンストレーション主導のカリキュラムの開始状態は、ランダム開始からの学習と比較して学習を著しく加速する。
- 低次元の物理状態から価値関数を学習することは、トレーニングを安定化させる。
- 対象中心の識別器は、タスク関連の特徴に焦点を当てることでGAILの信号伝達を改善する。
- 実機Kinova Jacoアームへのゼロショット転送は、固定配置で持ち上げ64%、積み上げ35%の成功を達成し、到達はテストされた軌道すべてで常に成功。
- ドメイン乱択化を伴うハイブリッドRL/ILは、大きな視覚的・動力学的変化に対して頑健性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。