[論文レビュー] Reinforcement Learning for Solving the Vehicle Routing Problem
この論文は、容量制約付きVRPのエンドツーエンド強化学習フレームワークを提案し、確率的方針を学習することで各インスタンスごとの再学習なしに競争力のある解を得て、中規模の問題において古典的ヒューリスティクスとOR-Toolsを上回る。
We present an end-to-end framework for solving the Vehicle Routing Problem (VRP) using reinforcement learning. In this approach, we train a single model that finds near-optimal solutions for problem instances sampled from a given distribution, only by observing the reward signals and following feasibility rules. Our model represents a parameterized stochastic policy, and by applying a policy gradient algorithm to optimize its parameters, the trained model produces the solution as a sequence of consecutive actions in real time, without the need to re-train for every new problem instance. On capacitated VRP, our approach outperforms classical heuristics and Google's OR-Tools on medium-sized instances in solution quality with comparable computation time (after training). We demonstrate how our approach can handle problems with split delivery and explore the effect of such deliveries on the solution quality. Our proposed framework can be applied to other variants of the VRP such as the stochastic VRP, and has the potential to be applied more generally to combinatorial optimization problems.
研究の動機と目的
- インスタンス特化の再学習なしでVRPを解くRLベースのフレームワークを開発する。
- VRPをMDPとして表現し、実現可能なルートを出力するポリシーを学習する。
- 中規模のVRPインスタンスで古典的ヒューリスティクスやOR-Toolsを上回るほぼ最適解を達成する。
- フレームワークが分割配送と動的バリアントを扱えることを示す。
- 他の組合せ最適化問題にも適用可能なスケーラブルなフレームワークを提案する。
提案手法
- 注意ベースのデコーダーを通じて解列を生成するパラメータ化された確率的ポリシーをモデル化する。
- セット状のVRP入力を扱うためにエンコーダRNNを用いず、入力埋め込みの集合と再帰デコーダを用いる。
- 文脈ベクトルを用いたアテンション機構を適用して次の目的地の確率分布を生成する。
- ポリシーをポリシー勾配法(actor-criticフレームワークは本稿で完全には詳述されていない)で訓練する。
- VRPの実現不可能な行動をマスクして実現可能性を強制し、必要に応じて緩和マスキングによる分割配送を許可する。
- 少量の追加計算で解の品質を向上させるビームサーチを実証する。
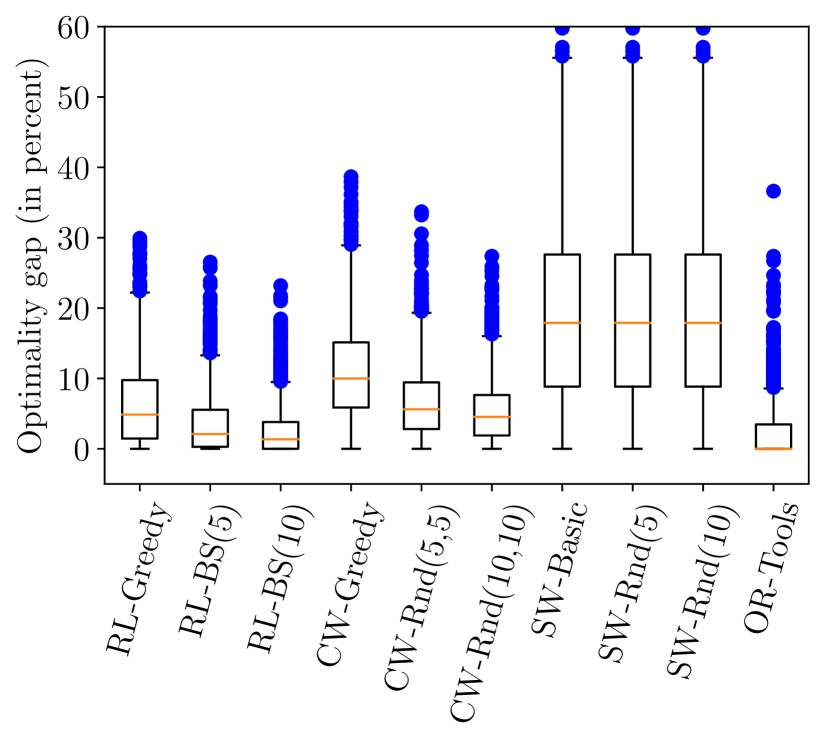
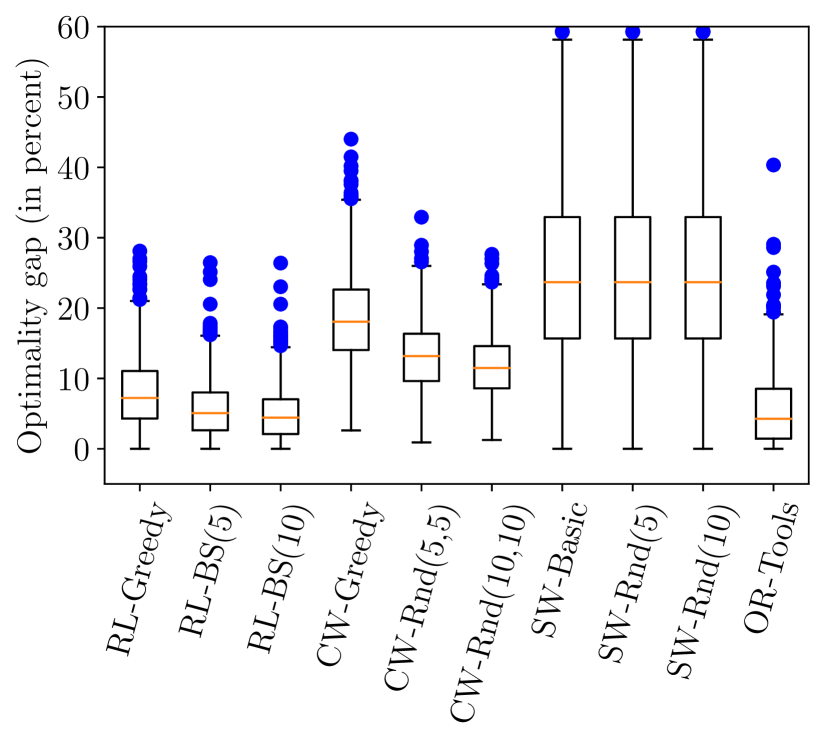
実験結果
リサーチクエスチョン
- RQ1エンドツーエンドのRLフレームワークはインスタンス特化の再学習なしでほぼ最適解に近いVRP解を生み出せるか?
- RQ2RLアプローチは解の品質と実行時間の点で古典的VRPヒューリスティクスおよびOR-Toolsと、VRPサイズの異なる場合でどのように比較されるか?
- RQ3モデルは分割配送と動的(確率的)VRPバリアントをサポートするか?
- RQ4集合型VRP入力に対してエンコーダなしの単純なアテンションベースのアーキテクチャで十分か?
- RQ5グリーディー対ビームサーチデコーダの解の品質への影響は?
主な発見
- RLフレームワークは Clarke–Wright および Sweep ヒューリスティクスを上回り、中規模VRPでOR-Toolsと競合する。
- ビームサーチはグリーディーデコードより解の品質を向上させ、RL-BSは多くのVRP50インスタンスでRL-greedyを上回る(例: 85.8%)。
- VRP10およびVRP20では、ほとんどのケースでビーム幅10で最適性ギャップが約5–13%となる。
- VRP50とVRP100では、基準法と比べて約61%のインスタンスで短いツアーを提供する。
- 緩和マスキングの下で多配送(分割配送)を許すことは、手作業での工夫なしに自然に現れる。
- 手法は問題サイズに対してスケールし、従来の距離行列を必要としない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。