[論文レビュー] Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process
この論文は Partial Dependence (PD) と Permutation Feature Importance (PFI) を、真の DGP の特性の推定量として形式化し、モデル学習の分散を考慮した分散と信頼区間の方法を開発します。学習再適合からの不確実性を捉える learner-PD および learner-PFI を導入します。
Scientists and practitioners increasingly rely on machine learning to model data and draw conclusions. Compared to statistical modeling approaches, machine learning makes fewer explicit assumptions about data structures, such as linearity. However, their model parameters usually cannot be easily related to the data generating process. To learn about the modeled relationships, partial dependence (PD) plots and permutation feature importance (PFI) are often used as interpretation methods. However, PD and PFI lack a theory that relates them to the data generating process. We formalize PD and PFI as statistical estimators of ground truth estimands rooted in the data generating process. We show that PD and PFI estimates deviate from this ground truth due to statistical biases, model variance and Monte Carlo approximation errors. To account for model variance in PD and PFI estimation, we propose the learner-PD and the learner-PFI based on model refits, and propose corrected variance and confidence interval estimators.
研究の動機と目的
- DGP との関連性をモデル解釈ツールへ結びつける必要性を動機づける。
- PD および PFI をデータ生成過程の真の特性の推定量として正式化する(DGP-PD, DGP-PFI)。
- PD/PFI の誤差をバイアス、分散(モデルとモンテカルロ)、および分散補正のアプローチを提案する。
- 学習プロセスの分散を考慮するために model-PD/PFI と learner-PD/PFI を区別する。
- 修正済み分散推定値と PD/PFI の信頼区間を含む推論ツールを提供する。
提案手法
- DGP-PD および DGP-PFI を、DGP の真の関数 f に適用された ground-truth の PD/PFI として定義する。
- PD と PFI を、バイアス、モデル分散、モンテカルロ誤差を組み込む推定量として表現し、バイアス-分散分解を導出する。
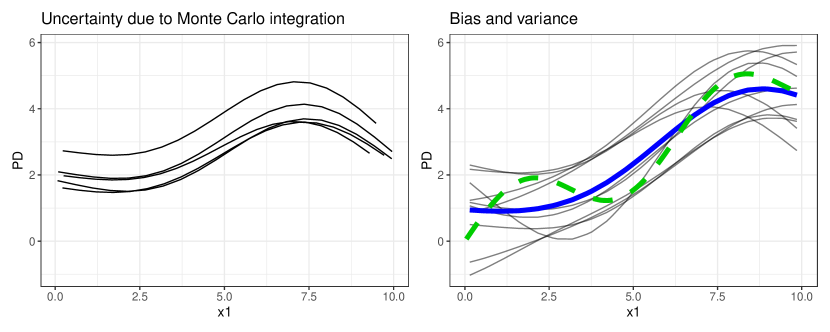
- 固定モデルの model-PD/model-PFI(固定モデル)と、複数のモデル再適合を平均化する learner-PD/learner-PFI(学習過程全体にわたる不確実性を反映する)を推論ターゲットとして導入する。
- モデル-PD およびモデル-PFI の分散推定量を導出し、点ごとの信頼区間を構成する。
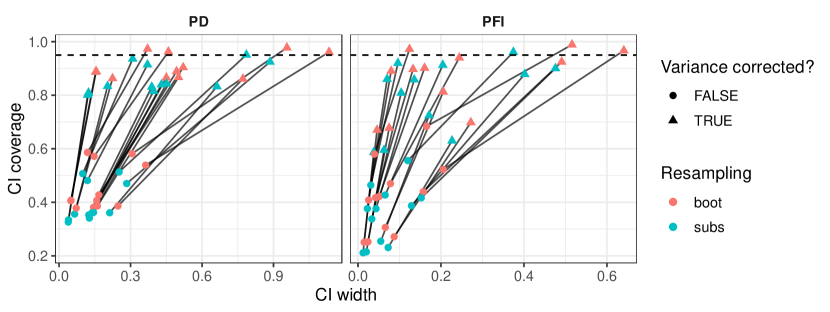
- learner-PD/learner-PFI の分散補正を提案し、学習過程の不確実性をよりよく反映させる(Nadeau-Bengio 型補正を伴う)。
- データ分割と複数の再適合を用いて learner-PD/ learner-PFI を計算する方法を論じ、モデル分散を捉える。
実験結果
リサーチクエスチョン
- RQ1PD と PFI を ground truth estimands(DGP-PD, DGP-PFI)を介してデータ生成過程に関連づけることは可能か?
- RQ2バイアス、モデル分散、モンテカルロ誤差が PD/PFI 推定量にどのように影響し、どのように定量化できるか?
- RQ3固定モデル(model-PD/PFI)とモデル再適合下(learner-PD/PFI)で、適切な分散推定量と信頼区間は何か?
- RQ4learner-PD/learner-PFI を導入してモデル分散を取り入れると、実務での解釈と不確実性の定量化はどう変わるか?
- RQ5再サンプリングを用いて複数のモデル適合を生成する際、分散推定を改善する補正は何か?
主な発見
- PD と PFI は、真の DGP の量(DGP-PD, DGP-PFI) の推定量として扱うことができる。
- PD/PFI の推定値には、バイアスと二つの分散源が含まれる:モデル分散とモンテカルロ (MC) 分散。
- Model-PD/Model-PFI は MC 分散のみを定量化し、学習過程の分散を無視するため、DGP についての推定が限定的。
- Learner-PD/Learner-PFI は複数のモデル再適合を平均化し、学習過程の全体的不確実性を捕捉し、DGP についての推定を改善する。
- learner-PD/PFI の分散推定には、リサンプリング(例:ブートストラップ)を用いる際の分散過小評価を解消する補正項が含まれている。
- learner-PD/PFI の信頼区間は、自由度がモデル適合数と等しい t 分布を用いて構成される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。