[論文レビュー] RePLan: Robotic Replanning with Perception and Language Models
RePLan は階層的な LLM ベースのプランナー、Vision-Language Model の知覚者、そして検証者を用いて、長期的なロボットタスクのリアルタイム再計画と報酬生成を可能にし、複数の環境で強力な性能を示します。
Advancements in large language models (LLMs) have demonstrated their potential in facilitating high-level reasoning, logical reasoning and robotics planning. Recently, LLMs have also been able to generate reward functions for low-level robot actions, effectively bridging the interface between high-level planning and low-level robot control. However, the challenge remains that even with syntactically correct plans, robots can still fail to achieve their intended goals due to imperfect plans or unexpected environmental issues. To overcome this, Vision Language Models (VLMs) have shown remarkable success in tasks such as visual question answering. Leveraging the capabilities of VLMs, we present a novel framework called Robotic Replanning with Perception and Language Models (RePLan) that enables online replanning capabilities for long-horizon tasks. This framework utilizes the physical grounding provided by a VLM's understanding of the world's state to adapt robot actions when the initial plan fails to achieve the desired goal. We developed a Reasoning and Control (RC) benchmark with eight long-horizon tasks to test our approach. We find that RePLan enables a robot to successfully adapt to unforeseen obstacles while accomplishing open-ended, long-horizon goals, where baseline models cannot, and can be readily applied to real robots. Find more information at https://replan-lm.github.io/replan.github.io/
研究の動機と目的
- 人間の介入を最小限に抑えつつ、自律で長期的なロボットタスクの実行を動機づけ、実現する。
- 言語モデルと視覚的根拠付けを介して高レベルの計画と低レベルの制御を橋渡しする。
- 認知フィードバックと検証を組み込み、計画の失敗と幻覚を低減する。
- 強化学習を用いない報酬生成フローでオープンエンドかつ多段階のタスク解決を実証する。
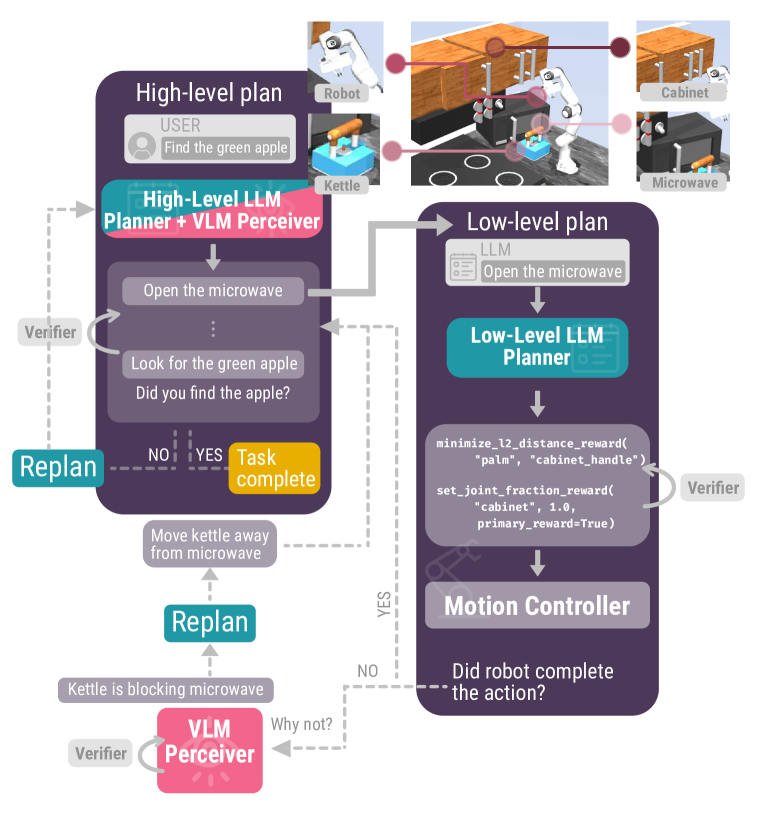
提案手法
- 高レベルの LLM プランナーが、ユーザー目標から抽象的なサブタスクを生成する。
- VLM Perceiver は、根拠づけられた状態観測と物体状態フィードバックを提供する。
- Low-Level LLM プランナーが、高レベルのサブタスクを低レベルの報酬関数へ変換する。
- モーションコントローラ(MuJoCo MPC)が、生成された報酬を用いて行動を実行する。
- LLM Verifier がプランナーの出力を検査・修正し、行動が目標に合致しているかを保証する。
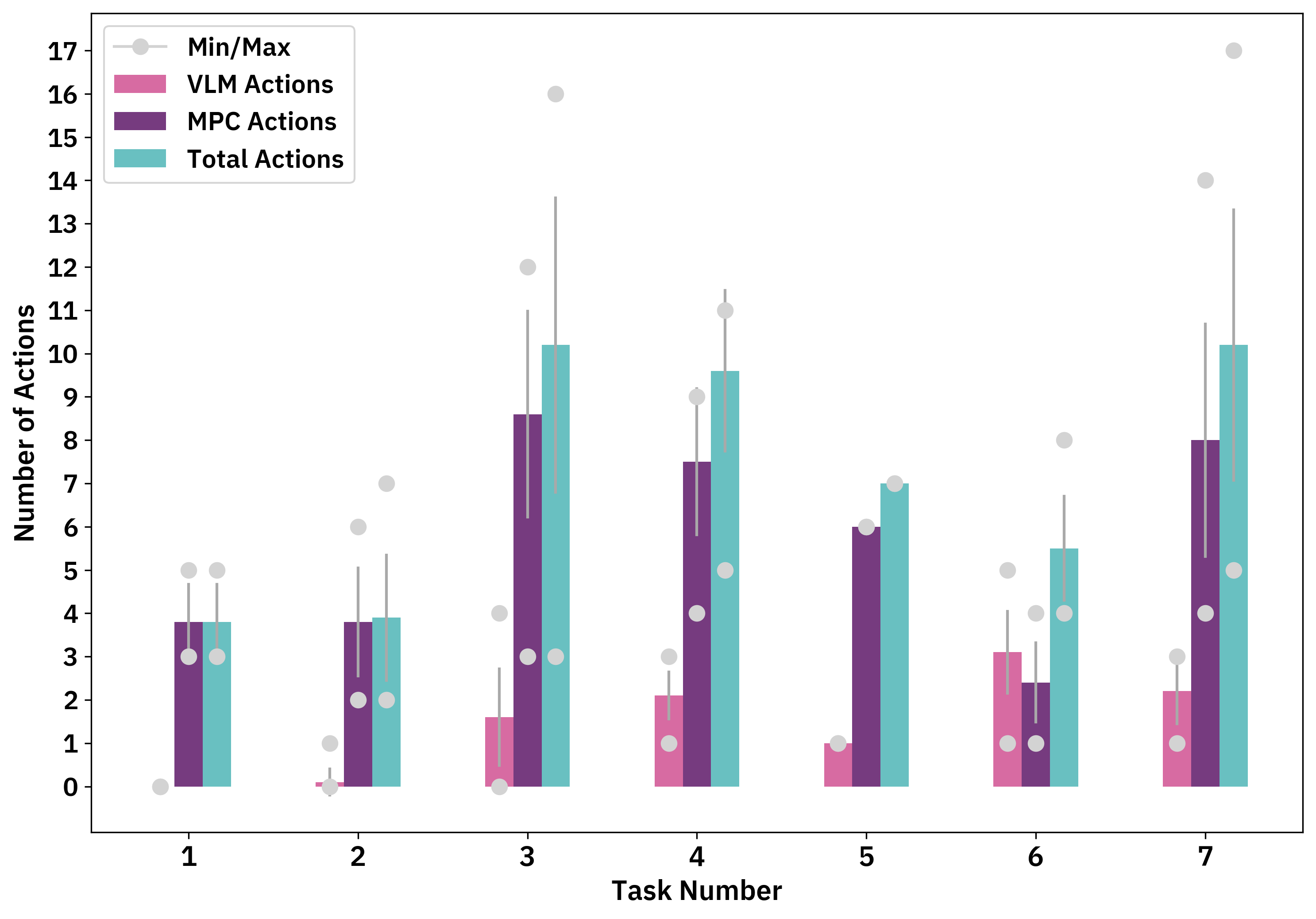
実験結果
リサーチクエスチョン
- RQ1LLM と VLM を用いた多層計画システムは、リアルタイムの再計画を伴う長期的かつオープンエンドなロボットタスクを実行できるか。
- RQ2認知の根拠付けと検証を組み込むことは、ベースラインの LLM ベースまたは非根拠付けアプローチと比較して、タスクの成功率と堅牢性を向上させるか。
- RQ3MPC ベースのロボット操作における制御のための LLM からの報酬生成パイプラインはどれほど効果的か。
- RQ4長期的なタスク性能に対して、検証器(Verifier)、知覚者(Perceiver)、再計画(Replan) のモジュールを削除した場合の影響はどれほどか。
主な発見
- RePLan は七つのタスクで平均成功率 88.6% を達成し、ベースラインよりも顕著に高い。
- Language to Rewards と比較して、RePLan は全体のタスク完了で 3.6×の改善を示した。
- アブレーションにより、Verifier、Perceiver、または Replan のいずれかを削除すると性能が顕著に低下し、特に Perceiver または Replan を削除した場合の低下が大きい。
- タスクレベルのパフォーマンスは変動する(例:タスク3が最も難しい)、障害物と報酬の優先順位付けの正確性などの課題を反映している。
- システムは、失敗後の再計画や未知の障害物への対応を含む、オープンエンドな問題解決を実証する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。