[論文レビュー] Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control
本論文は、ハイパーパラメータ調整、環境の確率性、およびランダムシードが Hopper-v1 および Half-Cheetah-v1 における DDPG と TRPO の再現性に与える影響を研究し、公正なベースラインと報告のための指針を示している。
Policy gradient methods in reinforcement learning have become increasingly prevalent for state-of-the-art performance in continuous control tasks. Novel methods typically benchmark against a few key algorithms such as deep deterministic policy gradients and trust region policy optimization. As such, it is important to present and use consistent baselines experiments. However, this can be difficult due to general variance in the algorithms, hyper-parameter tuning, and environment stochasticity. We investigate and discuss: the significance of hyper-parameters in policy gradients for continuous control, general variance in the algorithms, and reproducibility of reported results. We provide guidelines on reporting novel results as comparisons against baseline methods such that future researchers can make informed decisions when investigating novel methods.
研究の動機と目的
- 連続制御におけるポリシー勾配法の分散源を評価する。
- Hopper および Half-Cheetah で TRPO と DDPG のハイパーパラメータ感度を評価する。
- ハイパーパラメータとランダムシードが結果の再現性に与える影響を定量化する。
- 連続制御RLにおけるベースラインと実験手順の報告ガイドラインを提案する。
提案手法
- MuJoCo/OpenAI Gym 環境の Hopper-v1 および Half-Cheetah-v1 をテストベッドとして用いる。
- 既存研究の実装を用いて TRPO と DDPG を再現する。
- ポリシー網路アーキテクチャ、バッチサイズ、ステップサイズ、正則化、GAE のラムダ、報酬スケール、学習率などのハイパーパラメータを変化させる。
- 5000 イテレーションを 5 つのランダムシードで実行し、複数の試行で結果を分析する。
- 異なるシードと設定間で結果を比較して分散を評価する。
- 以前のベースラインと結果を比較し、平均リターンと標準偏差を含む複数の指標を報告する。
- 繰り返し試行を通じて環境の確率性が再現性に与える影響を調べる。
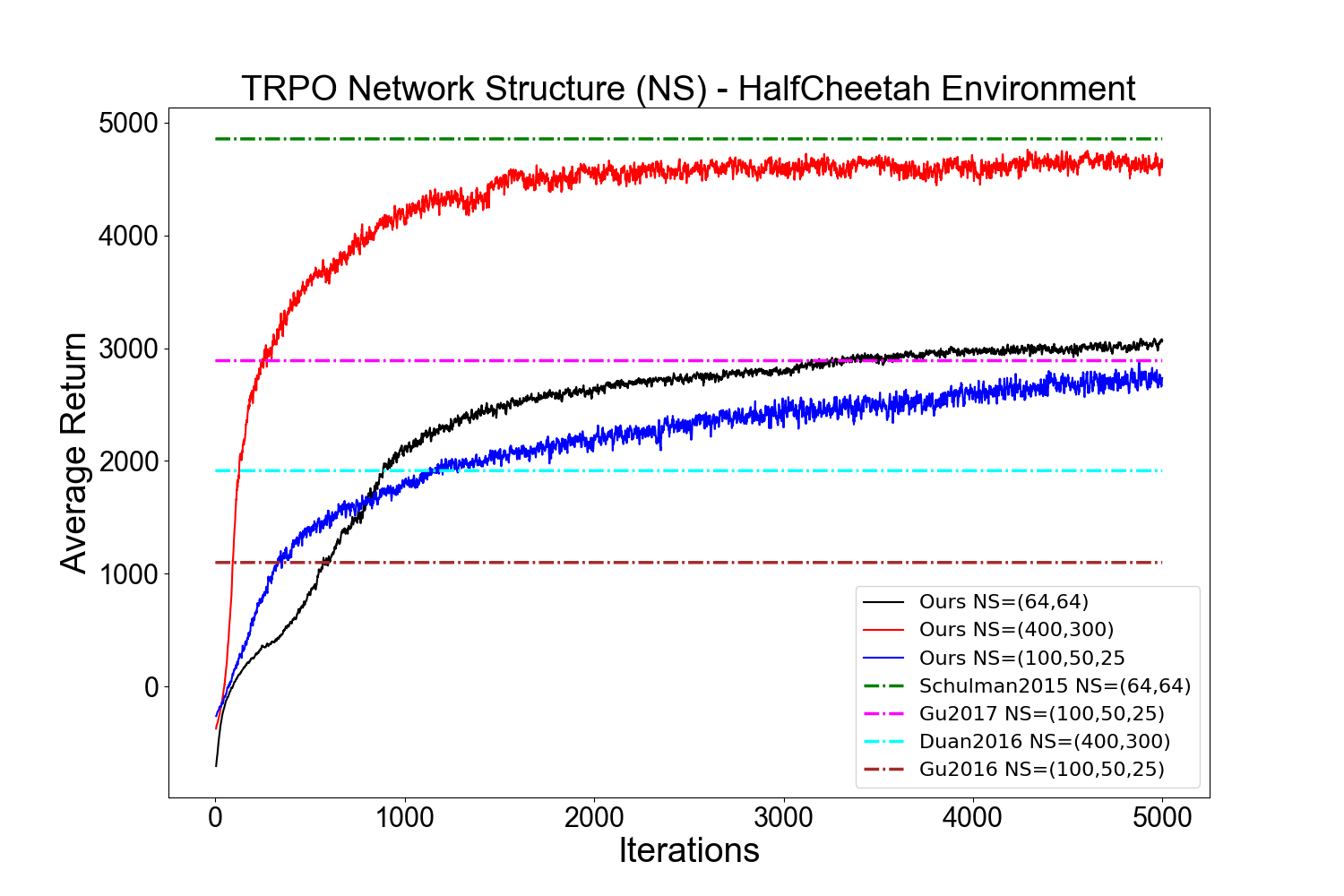
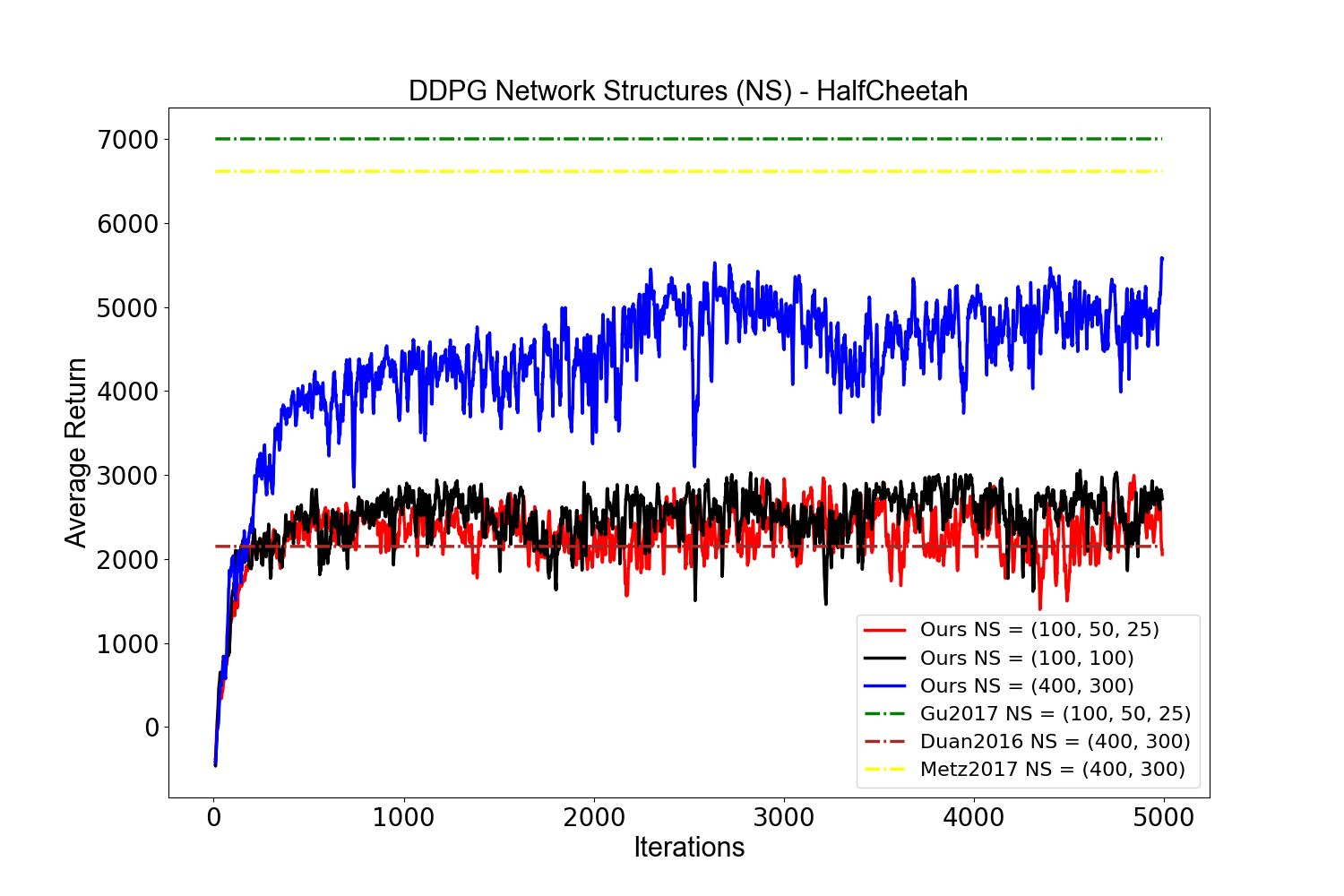
実験結果
リサーチクエスチョン
- RQ1ハイパーパラメータは Hopper および Half-Cheetah での TRPO および DDPG の性能と再現性にどう影響するか?
- RQ2報告結果のばらつきにおけるランダムシードと環境の確率性の役割は何か?
- RQ3連続制御RL手法の公正なベースラインを可能にするために必要な報告指標と実験プロトコルはどれか?
- RQ4異なる論文のベースライン結果は、慎重なチューニングと複数試行の平均化を経て一貫性を保つか?
主な発見
- ハイパーパラメータと確率性は TRPO と DDPG の両方で大きな性能分散を引き起こす。
- ネットワークアーキテクチャは Half-Cheetah に顕著な影響を与え、Hopper ではやや小さい。DDPG は Hopper で特に不安定である。
- 大きい TRPO のバッチサイズは小さいものより性能を改善する傾向が強いが、DDPG はバッチサイズの変更による利得が限られる。
- 報酬スケーリングと actor/critic の学習率は環境依存的な影響を持ち、Half-Cheetah と Hopper で結果が一貫していない。
- ハイパーパラメータを調整しても、ランダムシード間で結果は大きく変動するため、多数の試行で平均化する必要がある。
- 多くの先行研究は選択的な指標のみを報告しており、ベースラインを過小評価・過大評価する可能性がある。すべての指標とハイパーパラメータの包括的報告を推奨する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。