[論文レビュー] Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
この論文は Researchy Questions を紹介します。実世界の検索ログから抽出された、非-factoid、分解可能、複数視点の質問の大規模データセットで、LLMウェブエージェントがあいまいな情報ニーズにどう対処するかを研究するため、96kの質問と関連する分解計画およびクリック証拠を含みます。
Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
研究の動機と目的
- 現実世界のユーザー情報ニーズにおける未知の要素を明らかにする、複雑で非-factoid な質問の必要性を動機づける。
- 検索ログクエリを分解的なQAデータセットへ採掘、フィルタリング、重複排除する構築パイプラインを説明する。
- LLMエージェントの挙動を評価・根拠付けるために、階層的分解と証拠シグナル(クリックされたURL)を提供する。
- Researchy Questions による分解的回答の利点とユーザーの検索行動への洞察を示すベースライン評価を提供する。
提案手法
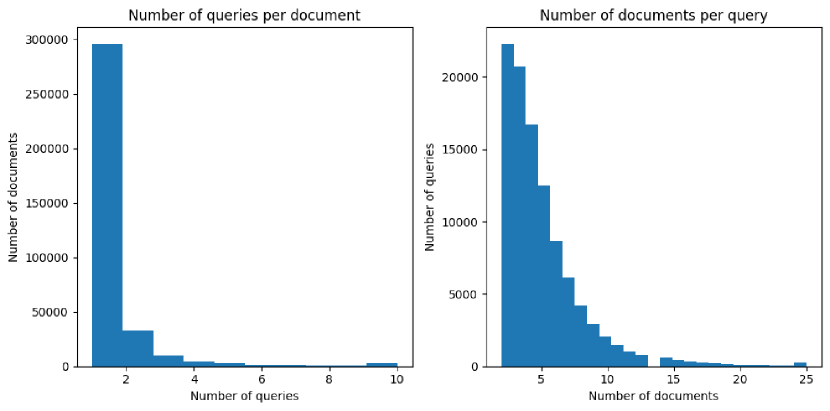
- 実世界の英語検索ログを採掘して、少なくとも50件の異なる出現と複数のクリックURLを含む候補質問を収集する。
- 分類器とGPT-4ラベリングを用いて、分解的回答に適した非-factoidのオープンドメイン質問を段階的にフィルタリングして抽出する。
- ANCEベースの埋め込みとクラスタリングを用いたクエリ意図のアグロメラティブな重複排除を行い、グループの代表ヘッドを生成する。
- 最終的なGPT-4ベースの品質チェックを適用してあいまい・不完全・仮定的、または安全でない質問を除外し、96k問を得る。
- 各質問に対して2レベルの階層的分解を提供し、証拠シグナルとして対応するClueWeb22のクリックURLを公開する。

実験結果
リサーチクエスチョン
- RQ1Researchy Questions とは何か、従来の事実問ベンチマークとどう differs するのか?
- RQ2検索ログから採掘された非-factoid、分解可能な質問は、LLMウェブエージェントの未知の未知を効果的に明らかにできるか?
- RQ3階層的分解は、直接回答と比べて、長文・マルチドキュメントクエリの検索と統合を改善するか?
- RQ4どのような行動シグナル(例:クリック、セッション長)が Researchy Questions におけるより大きな労力と複雑さを示すか?
- RQ5分解的回答技術は、長文・多視点の質問に対して直接回答と比較してどうか?
主な発見
- Researchy Questions は非-factoid、分解的、かつ多視点であり、1段落の回答を超える相当な研究努力を必要とする。
- ユーザーは Researchy Questions に対してより長い時間とクリックを要し、情報検索の努力と多様な証拠ニーズが存在することを示す。
- GPT-4ベースの分解アプローチ(特に分解されたファクタリング法)は、長文・多面的な質問に対する直接のクローズドブック回答より優れている。
- 分解的技法は長文の質問に対して正確性と品質の向上をもたらし、Wikihow や Researchy Questions のデータセットで顕著な改善が見られる。
- 約96k問が公開され、それぞれ2レベル階層の計画とベクトルベースの重複排除ヘッド、及び関連するClueWeb22のクリックURLが付随している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。