[論文レビュー] Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey
この論文は2019年から2024年までの大規模分散深層学習におけるリソース割り当てとワークロードスケジューリング戦略を調査し、大規模モデル訓練のケーススタディを含む。
With rapidly increasing distributed deep learning workloads in large-scale data centers, efficient distributed deep learning framework strategies for resource allocation and workload scheduling have become the key to high-performance deep learning. The large-scale environment with large volumes of datasets, models, and computational and communication resources raises various unique challenges for resource allocation and workload scheduling in distributed deep learning, such as scheduling complexity, resource and workload heterogeneity, and fault tolerance. To uncover these challenges and corresponding solutions, this survey reviews the literature, mainly from 2019 to 2024, on efficient resource allocation and workload scheduling strategies for large-scale distributed DL. We explore these strategies by focusing on various resource types, scheduling granularity levels, and performance goals during distributed training and inference processes. We highlight critical challenges for each topic and discuss key insights of existing technologies. To illustrate practical large-scale resource allocation and workload scheduling in real distributed deep learning scenarios, we use a case study of training large language models. This survey aims to encourage computer science, artificial intelligence, and communications researchers to understand recent advances and explore future research directions for efficient framework strategies for large-scale distributed deep learning.
研究の動機と目的
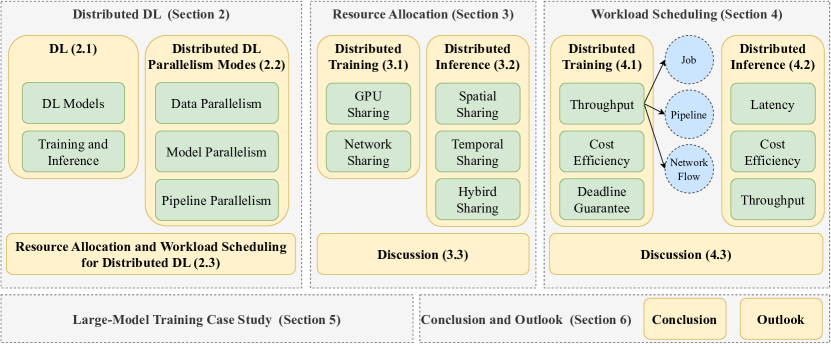
- 大規模分散 DL のリソース割り当てとワークロードスケジューリングのフレームワークを系統的にレビューする。
- リソースタイプ(GPU、ネットワーク)とスケジューリングの粒度(ジョブ、パイプライン、コーフロー)に跨る課題を分析する。
- 既存の技術を比較し、データセンターでの実用展開を導く洞察を提供する。
- 大規模モデル分散訓練のケーススタディで適用を示す。
- 効率性とスケーラビリティを改善する未来の研究方向を提案する。
提案手法
- 2019–2024年の分散DLのリソース管理とスケジューリングに関する系統的文献レビューを実施する。
- リソースタイプ(GPU共有、ネットワーク共有)とスケジューリングの粒度(ジョブ、パイプライン、コフロー)で戦略を分類する。
- 学習および推論ワークフローと複数の性能目標を軸に分析を整理する。
- 実用例を示すために大規模モデル分散訓練のケーススタディを提供する。
- 課題の総合と今後の研究を導く主要な洞察の提示。
実験結果
リサーチクエスチョン
- RQ1大規模分散DLにおけるリソース割り当てとワークロードスケジューリングの主要な課題は何か?
- RQ2GPU共有とネットワーク帯域共有の戦略にはどんなものがあり、スケジューリングの粒度によってどう異なるか?
- RQ3これらのフレームワーク戦略を実際にデータセンターの訓練および推論性能の向上にどう適用できるか?
- RQ42019年から2024年の文献調査からどんな洞察と未来の方向性が生まれるか?
主な発見
- この調査は、学習と推論の両方にわたって、大規模分散DLのリソース割り当てとワークロードスケジューリングのフレームワークを包括的に整理しています。
- GPU共有、ネットワーク帯域共有、ジョブ・パイプライン・ネットワークフローレベルでのスケジューリングに関する重要な課題を強調しています。
- 関連する調査を比較し、計算と通信の共同最適化を強調することでギャップを埋めています。
- データセンターでの実践的適用を示すために大規模モデル分散訓練のケーススタディを提供します。
- 効率的なフレームワーク戦略のためのギャップを特定し、今後の研究方向を提案します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。