[論文レビュー] Resurrecting Recurrent Neural Networks for Long Sequences
この論文は、 Linear Recurrent Units (LRU) を用いた深い RNN アーキテクチャが、慎重な線形化、対角化、安定した初期化、および正規化を通じて、Long Range Arena のような長距離シーケンスタスクで深い状態空間モデルと同等の性能を発揮しつつ、トレーニング効率を維持できることを示している。
Recurrent Neural Networks (RNNs) offer fast inference on long sequences but are hard to optimize and slow to train. Deep state-space models (SSMs) have recently been shown to perform remarkably well on long sequence modeling tasks, and have the added benefits of fast parallelizable training and RNN-like fast inference. However, while SSMs are superficially similar to RNNs, there are important differences that make it unclear where their performance boost over RNNs comes from. In this paper, we show that careful design of deep RNNs using standard signal propagation arguments can recover the impressive performance of deep SSMs on long-range reasoning tasks, while also matching their training speed. To achieve this, we analyze and ablate a series of changes to standard RNNs including linearizing and diagonalizing the recurrence, using better parameterizations and initializations, and ensuring proper normalization of the forward pass. Our results provide new insights on the origins of the impressive performance of deep SSMs, while also introducing an RNN block called the Linear Recurrent Unit that matches both their performance on the Long Range Arena benchmark and their computational efficiency.
研究の動機と目的
- Transformers および SSM が強みを示している長距離シーケンスモデリングへの RNN の活用を動機づける。
- 深い RNN が長距離タスクで深い SSM に匹敵できるかを識別する。
- RNN の長距離推論に影響を与えるアーキテクチャ選択と初期化を分離・アブレーションする。
- 長いシーケンスで競争力のある性能と効率を実現する principled(原則に基づく)な RNN デザイン(LRU)を提供する。
提案手法
- Long Range Arena ベンチマークで vanilla RNN と SSMs(例:S4)を比較する。
- SSM 層を線形 RNN 層に置換し、非線形の MLP ブロックを積み重ねて Linear Recurrent Unit(LRU)を形成する。
- 再帰における非線性を除去すると深いアーキテクチャで性能が向上することを実証する。
- 学習を安定化させ、長距離モデリングを可能にするために複素対角再帰行列と指数的パラメータ化を導入する。
- 非常に長い-range タスクでトレーニングを安定化させるために隠れアクティベーションの正規化を適用する。
- 対角化、初期化スペクトル、正規化がタスク性能に及ぼす影響を示すアブレーションを提供する。
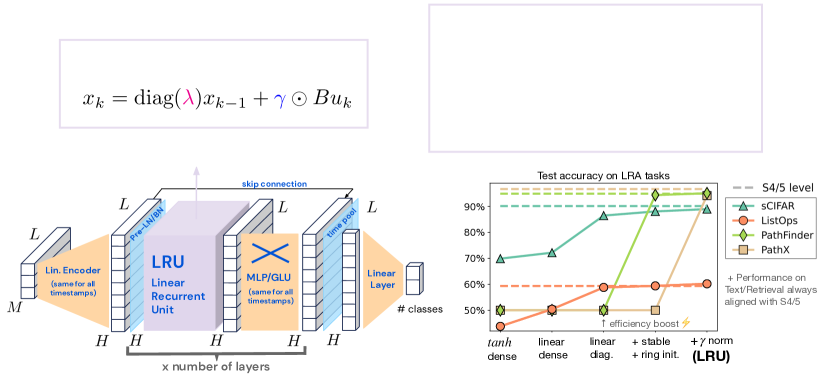
実験結果
リサーチクエスチョン
- RQ1深い RNN は長距離推論タスクで深い連続時間 SSM の性能に匹敵できるか?
- RQ2SSM 風の性能を RNN で達成するために必要なアーキテクチャ的・初期化的変更は何か?
- RQ3適切な対角化と正規化を伴う線形再帰は長いシーケンスの効率的なトレーニングを可能にするか?
- RQ4固有値の安定化戦略は LR Us の長距離依存学習にどのように影響するか?
主な発見
- 深い線形再帰は再帰の非線形性を持たないことで、いくつかの Long Range Arena タスクで非線形 RNN バリアントを上回ることがある。
- 複素数値対角行列による再帰の対角化はトレーニングを加速し、LRA タスクで S4/S5 の性能に匹敵することがある。
- 対角スペクトルの指数的パラメータ化は安定したトレーニングを可能にし、特に Pathfinder のような難しいタスクで長距離推論を改善する。
- 前方伝搬時の隠れアクティベーションの正規化は、長距離タスクで深い SSM とのギャップを縮めるのに重要である。
- 単位円盤の近くのスペクトルで初期化され、正規化が施されると、LRU は LRA ベンチマークで深い SSM と競合する性能を達成する。
![Figure 4: Evolution of $x\in\mathbb{R}^{3}$ under impulse input $u=(1,0,0,\dots,0)\in\mathbb{R}^{16k}$ . Plotted in different colors are the 3 components of $x$ . $\Lambda$ has parameters $\nu_{j}=0.00005$ and $\theta_{j}$ sampled uniformly in $[0,2\pi]$ or with small phase $[0,\pi/50]$ . For small](https://ar5iv.labs.arxiv.org/html/2303.06349/assets/x6.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。