[論文レビュー] Rethinking and Improving Relative Position Encoding for Vision Transformer
この論文は、自己注意機構における方向性の相対的距離とクエリ-相対的位置埋め込み相互作用をモデル化することで、ビジョントランスフォーマーの性能を向上させる画像固有の相対的位置埋め込み(iRPE)手法を提案する。この手法は、ハイパーパramータのチューニングなしでImageNetで最大1.5%のトップ1精度向上とCOCOで1.3%のmAP向上を達成し、画像分類において絶対位置埋め込みを効果的に置き換えられることを示している一方で、物体検出においては依然として不可欠であることが明らかになった。
Relative position encoding (RPE) is important for transformer to capture sequence ordering of input tokens. General efficacy has been proven in natural language processing. However, in computer vision, its efficacy is not well studied and even remains controversial, e.g., whether relative position encoding can work equally well as absolute position? In order to clarify this, we first review existing relative position encoding methods and analyze their pros and cons when applied in vision transformers. We then propose new relative position encoding methods dedicated to 2D images, called image RPE (iRPE). Our methods consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight. They can be easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT and DETR obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparameters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding. Code and models are open-sourced at https://github.com/microsoft/Cream/tree/main/iRPE.
研究の動機と目的
- 絶対位置埋め込みと比較して、相対的位置埋め込み(RPE)がビジョントランスフォーマーで有効であるかどうかの論争を解消すること。
- 1次元RPEの拡張に起因する制限を克服するため、2次元画像データに特化したRPE手法を設計すること。
- 方向性の相対的距離とクエリ-RPE相互作用を組み込むことで、ビジョントランスフォーマーにおける空間的インダクティブバイアスのモデル化を向上させること。
- 計算コストを著しく増加させることなく、軽量で即座に統合可能なソリューションを提供すること。
- 画像分類と物体検出タスクにおけるRPEの役割を実証的に明確にすること。
提案手法
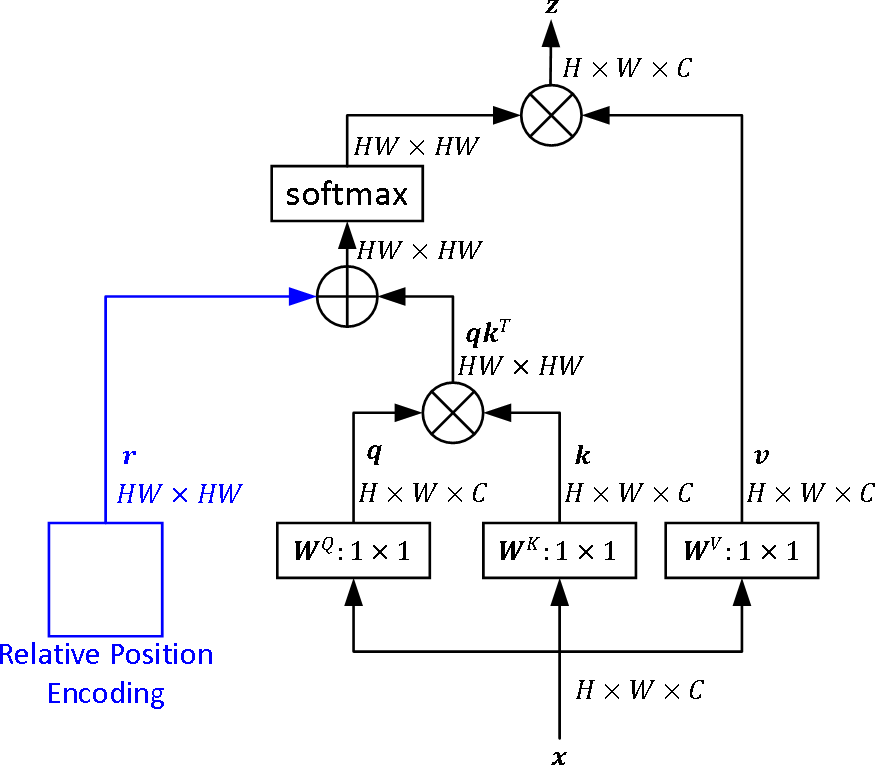
- 2次元画像に特化した、水平方向および垂直方向の相対的距離を明示的にモデル化する4つの新しい相対的位置埋め込み手法(iRPE)を提案する。
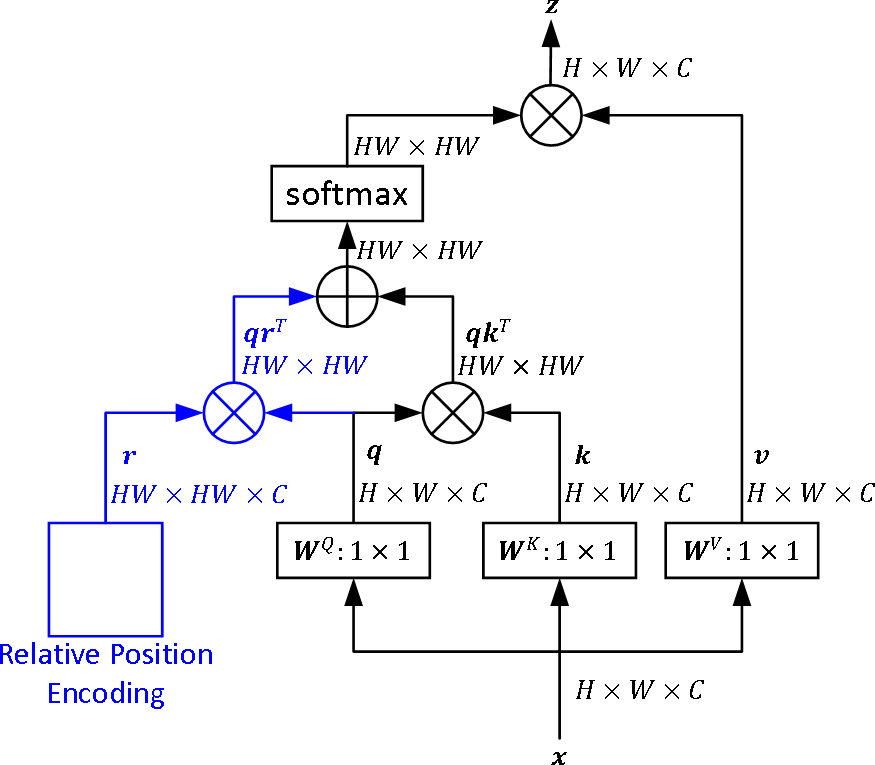
- クエリ特徴と相対的位置埋め込みを組み合わせることで注意重みを計算する文脈的積み込み機構を導入し、相互作用のモデル化を強化する。
- 複数のヘッドにわたって共通のRPEテーブルを採用することで、パラメータ数を削減しながらも性能を維持する。
- 計算量をO(n²d)からO(nkd)に低減(k ≪ n)することで、高解像度入力へのスケーラビリティを向上させる。
- 標準的なトランスフォーマーブロックに直接iRPEモジュールを統合することで、互換性と統合の容易さを確保する。
- 学習可能なルックアップテーブルを用い、高さおよび幅方向の各相対オフセットに対して固有のベクトルを割り当てる。
実験結果
リサーチクエスチョン
- RQ1ビジョントランスフォーマーを用いた画像分類タスクにおいて、相対的位置埋め込みが絶対位置埋め込みを効果的に置き換えられるか?
- RQ2なぜ相対的位置埋め込みは、画像分類と物体検出といった異なるビジョンタスクで一貫しない性能を示すのか?
- RQ32次元視覚トランスフォーマーにおける方向性の相対的距離モデリングは、注意パターンにどのように影響を与えるか?
- RQ4物体検出やセマンティックセグメンテーションのような高解像度ビジョンタスクにRPEを適用した際の計算コストへの影響は何か?
- RQ5クエリ-RPE相互作用は、モデルの局所的およびグローバルな空間的依存関係を捉える能力にどのように寄与するか?
主な発見
- 提案されたiRPE手法は、ハイパーパramータのチューニングなしで、DeiT-SがImageNetで1.5%のトップ1精度向上、DETR-ResNet50がCOCOで1.3%のmAP向上を達成した。
- 画像分類タスクでは、相対的位置埋め込みが絶対位置埋め込みを完全に置き換え可能であり、優れたもしくは同等の性能を達成できる。
- 物体検出においては、正確な物体定位に不可欠なインダクティブバイアスを提供するため、絶対位置埋め込みが依然として必要である。
- 方向性の相対的距離モデリングは、特に浅い層で周囲のパッチに注目するモデルの挙動を強化し、注意パターンを顕著に改善する。
- クエリ-RPE相互作用を組み込んだ文脈的積み込み機構は、畳み込み型インダクティブバイアスを模倣する能力を向上させ、局所的な空間構造を捉える能力を強化する。
- 複数の注意ヘッドに共通のRPEを採用することで、非共有バージョンと同等の性能を達成しつつ、パラメータ数を削減し、精度の低下を最小限に抑えることができる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。