[論文レビュー] Rethinking BiSeNet For Real-time Semantic Segmentation
この論文は STDC-Seg を、追加の推論コストなしに高速で正確なリアルタイム意味分割を実現するための Short-Term Dense Concatenate バックボーンと Detail Guidance デコーダを備えた提案として紹介します。
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
研究の動機と目的
- 効率的なバックボーン(STDC モジュール)を設計し、パラメータ数と計算量を抑えつつ拡張可能な受容野を提供する。
- Detail Guidance によって低レベル特徴へ空間ディテール学習を統合し、追加の空間パスを不要にする。
- 高レベルの意味特徴をガイド付きの低レベルディテールと統合して境界の保持を改善する。
- エンドツーエンドの単一ストリームアーキテクチャを用いて、Cityscapes、CamVid などの実時間セグメンテーションの速度と精度のバランスを強化する。
提案手法
- 複数のブロックからの多スケール特徴マップを、段階的に小さくなるカーネルで連結して拡張可能な受容野と FLOPs の削減を実現する STDC モジュールを導入する。
- 中間マップを共通解像度にダウンサンプリングした後、連結によって STDC ブロック出力をダウンサンプリングして融合する。
- デコーダーでは Detail Aggregation モジュールを介して Detail Guidance を適用し、ラプラスベースの処理から生成されたバイナリディテールグラウンドトゥルースと Detail Head を用いて低レベル特徴を導くが、推論コストを追加しない。
- segmentation loss に加えて detail loss(L_detail = L_Dice + L_BCE)を用いて低レベル特徴を空間ディテールに向けて導く訓練を行い、推論時にはセグメンテーション経路のみを使用する。
- マルチスケールの文脈を得るために BiSeNet に着想を得たコンテキストパスを用い、Feature Fusion モジュールを介してデコーダーと融合する。
実験結果
リサーチクエスチョン
- RQ1提案された STDC バックボーンは、リアルタイムセグメンテーションの高速性を大幅に高めつつ、軽量バックボーンと比較して競争力のあるセグメンテーション精度を達成できるか。
- RQ2Detail Guidance モジュールは、推論時間を増加させることなく境界と小さな物体の識別を改善できるか。
- RQ3STDC-Seg は Cityscapes および CamVid において、mIoU と FPS の観点で最先端のリアルタイムセグメンテーション手法とどのように比較されるか。
- RQ4STDC ブロックの数は精度と速度にどのような影響を与えるか。
- RQ5Detail Guidance を備えた単一ストリームのデコーダーは、BiSeNet 系の二路アーキテクチャを置換するのに十分か。
主な発見
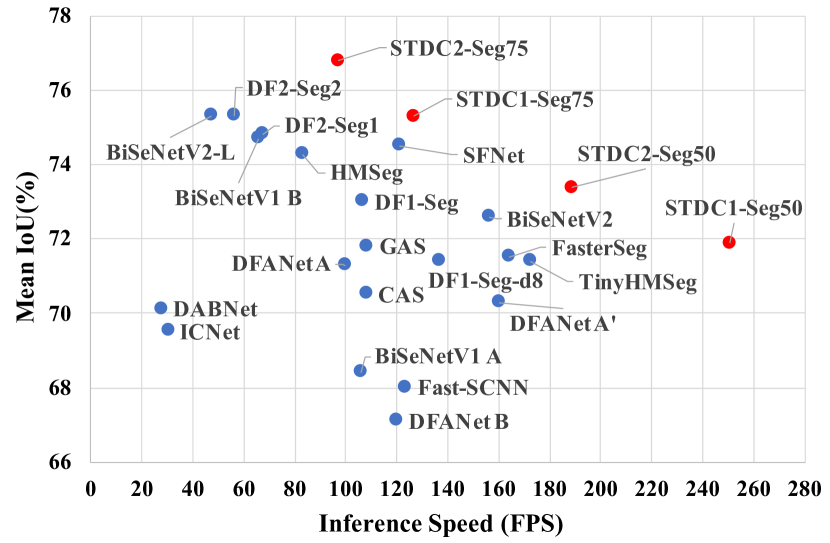
- STDC2-Seg50 は Cityscapes で 512x1024 入力時に 188.6 FPS、mIoU は 73.4% を達成。
- STDC1-Seg50 は Cityscapes で 512x1024 入力時に 250.4 FPS、mIoU は 71.9% を達成。
- STDC2-Seg75 は Cityscapes で 768x1536 入力時に 97.0 FPS、mIoU は 76.8% を達成。
- Cityscapes の検証セットでは STDC2-Seg75 が 97.0 FPS で 77.0% mIoU を達成(768x1536 入力)
- STDC1-Seg は CamVid(720x960)で 197.6 FPS、mIoU は 73.0% を達成。
- Detail Guidance は境界と小さな物体の識別を推論コストを増やさずに改善し、空間的なディテールの精度を向上させ、計算量あたりの精度で Spatial Path ベースの構成を上回る。
![Figure 2: Illustration of architectures of BiSeNet [ 28 ] and our proposed approach. (a) presents Bilateral Segmentation Network (BiSeNet [ 28 ] ), which use an extra Spatial Path to encode spatial information. (b) demonstrates our proposed method, which use a Detail Guidance module to encode spatia](https://ar5iv.labs.arxiv.org/html/2104.13188/assets/figures/architecture-comparison.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。