[論文レビュー] Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
XTR はマルチベクトル検索におけるトークン取得を再定義し、取得済みトークンのみを用いて文書を直接スコア付けすることで gathering 段階を排除し、スコアリングコストを大幅に削減しつつ BEIR/LoTTE で最先端、MS MARCO で強力な性能を達成します。
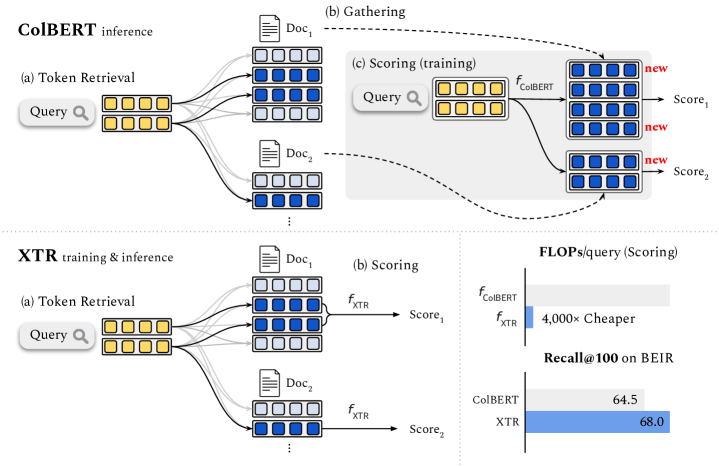
Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
研究の動機と目的
- 伝統的な三段階のマルチベクトル取得パイプライン(トークン取得、 gathering、スコアリング)の簡略化を動機づける。
- salient な文書トークンを優先して取得する訓練目的を提案する。
- retrieved トークンの上で動作し、欠損トークンを補完することで全文書スコアを近似するスコアリング機構を開発する。
- 蒸留やハードネガティブマイニングなしで BEIR と LoTTE における最先端のゼロショットIR性能を示す。
- ColBERT に比べてスコアリング計算を大幅に削減しつつ、ドメイン内の性能を維持することを示す。
提案手法
- XTR を導入する。新規のバッチ内アライメント戦略を持つ文脈化トークンリトリーバで、A_ij=1 はクエリトークン i に対して文書トークン d_j が top-k_train 内で取得された場合のみ成立する。
- f_XTR(Q,D) = (1/Z) sum_i max_j A_ij q_i^T d_j を定義する。Z は少なくとも一つの文書トークンを取得するクエリトークンの数をカウントする正規化子。
- 推論時には retrieved トークンのみを用いて文書をスコア付け gathering 段階を排除し、効率のために取得スコアを再利用する。
- f_XTR' に欠損類似度補完を導入し、 non-retrieved トークンのスコアを推定し、top-k' retrieved スコアに基づく上限を提供する。
- 通常のクロスエントロピーロスで訓練するが、XTR スコアリング関数を用い、関連文書のトークンがより頻繁に取得されるようにする。
- 欠損類似度の上限補完 m_i を最後に retrieved したトークンのスコアを用いて tighten する。
実験結果
リサーチクエスチョン
- RQ1トークン取得だけでマルチベクトル検索における文書ランク付けは競合的または優越的になり得るか?
- RQ2効果的な下流スコアリングのために salient な文書トークンを優先的に取得するようトークン取得を訓練するにはどうすべきか?
- RQ3 retrieved トークンのみに依存し、欠損類似度の補完でスコアリングを一桁以上安くすることは可能か?
- RQ4ゼロショットベンチマーク(BEIR/LoTTE)は提案された訓練 Objective と欠損類似度補完の恩恵を受けるか?
- RQ5蒸留や追加の事前訓練なしに多言語検索タスクにおける XTR の影響はどうなるか?
主な発見
- XTR は蒸留やハードネガティブマイニングなしで BEIR におけるゼロショット設定で最先端の性能を達成。
- XTR は retrieved トークンに依存し gathering 段階を排除することで、ColBERT より最大で二〜三桁の計算量削減を実現し、スコアリング計算を大幅に削減。
- バッチ内トークン取得目的で訓練することで top-k retrieved トークン中の金標準トークンのリコールが大幅に改善。
- XTR は ColBERT と比較してより良いコンテキストトークン取得を示し、金標準トークンの取得確率とコンテキスト一致を改善。
- Multilingual XTR (mXTR) は MIRACL でコントラスト学習ベースライン(例:mContriever)を上回り、追加の事前訓練なしで強力な多言語検索を示す。
- 補完ベースのスコアリング(XTR')は計算をさらに削減しつつ競争力のある結果を達成でき、k' が増えるにつれてリコールが改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。