[論文レビュー] Rethinking Vision Transformers for MobileNet Size and Speed
EfficientFormerV2は、視覚 transformers がモバイルデバイス上でMobileNet規模のサイズと速度に匹敵しつつ、より高い精度を達成できることを示す。これは、モデルサイズと遅延を細粒度で考慮したアーキテクチャ探索を共同で最適化することによる。
With the success of Vision Transformers (ViTs) in computer vision tasks, recent arts try to optimize the performance and complexity of ViTs to enable efficient deployment on mobile devices. Multiple approaches are proposed to accelerate attention mechanism, improve inefficient designs, or incorporate mobile-friendly lightweight convolutions to form hybrid architectures. However, ViT and its variants still have higher latency or considerably more parameters than lightweight CNNs, even true for the years-old MobileNet. In practice, latency and size are both crucial for efficient deployment on resource-constraint hardware. In this work, we investigate a central question, can transformer models run as fast as MobileNet and maintain a similar size? We revisit the design choices of ViTs and propose a novel supernet with low latency and high parameter efficiency. We further introduce a novel fine-grained joint search strategy for transformer models that can find efficient architectures by optimizing latency and number of parameters simultaneously. The proposed models, EfficientFormerV2, achieve 3.5% higher top-1 accuracy than MobileNetV2 on ImageNet-1K with similar latency and parameters. This work demonstrate that properly designed and optimized vision transformers can achieve high performance even with MobileNet-level size and speed.
研究の動機と目的
- ViTが高精度だが、モバイル展開には大きすぎるまたは遅すぎるという現実的なギャップを動機づけ、解決する。
- MobileNet系と同等のパラメータ数と潜在遅延で、モバイル向けのViTバックボーンを設計する。
- モデルサイズと推論速度の双方を最適化する、細粒度の共同探索戦略を提案する。
- ImageNet-1Kでパレート最適のアーキテクチャを実証し、検出・セグメンテーションなどの下流タスクで検証する。
提案手法
- 4段階の階層バックボーンアーキテクチャを備えたEfficientFormerV2を導入する。
- 残差局所トークンミキサーを、局所性を持つ深さ方向畳み込みを含む統一FFNに置換する。
- V内の局所情報を含むMHSAの改善とTalking Head接続を検討する。
- Stride AttentionとDual-Path Attention Downsamplingを用いて、精度と遅延をバランスさせた高解像度アテンションを可能にする。
- 精度・モデルサイズ・遅延を組み合わせるMobile Efficiency Score (MES)を提案し、共同探索を推進する。
- 弾性深さ・幅・FFN展開比を持つ探索可能なスーパネットを構築し、MESと精度を最適化するアクション群を前面に据えた評価ベースのNASを実行する。
実験結果
リサーチクエスチョン
- RQ1Can vision transformers be designed to match MobileNet-level size and speed without sacrificing accuracy?
- RQ2What architectural changes enable mobile-friendly ViTs with competitive latency on real devices?
- RQ3How can NAS jointly optimize model size and latency for ViTs to achieve Pareto-optimal trade-offs?
- RQ4Do EfficientFormerV2 variants translate to improvements in downstream tasks such as detection and segmentation?
主な発見
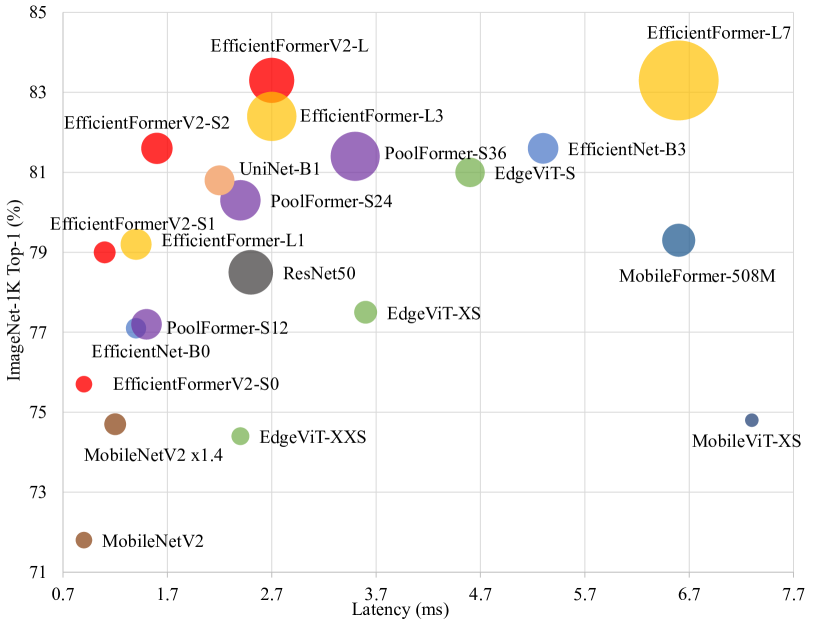
- EfficientFormerV2-S0 achieves higher top-1 accuracy than MobileNetV2 at similar latency and parameter counts on ImageNet-1K.
- EfficientFormerV2-S1 is roughly 2x smaller and 1.3x faster than EfficientFormer-L1 while maintaining similar performance.
- EfficientFormerV2-S2 outperforms several mobile-friendly baselines in accuracy with comparable latency.
- Downstream tasks show improvements in Mask R-CNN on COCO and semantic segmentation on ADE20K when using EfficientFormerV2 backbones.
- The joint MES-based search yields Pareto-optimal models that balance size, latency, and accuracy better than single-metric optimizations.
- The proposed Stride Attention and Dual-Path Attention Downsampling significantly reduce latency while preserving accuracy gains.
![Figure 2: Network architectures. We consider three metrics, i.e. , model performance, size, and inference speed, and study the models that improve any metric without hurting others. (a) Network of EfficientFormer [ 47 ] that serves as a baseline model. (b) Unified FFN (Sec. 3.1 ). (c) MHSA improveme](https://ar5iv.labs.arxiv.org/html/2212.08059/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。