[論文レビュー] Rethinking White-Box Watermarks on Deep Learning Models under Neural Structural Obfuscation
この論文は、ダミーニューロンに基づくニューラル構造の不透明化が、非消失型ダミーニューロンを導入してウォーターマーク検証を撹乱することで、モデルの有用性を損なうことなく九つの主流のホワイトボックスDNNウォーターマークを無効化できることを明らかにする。また、生成/注入のプリミティブとステルスな不透明化を実現するカモフラージュ手法を提案する。
Copyright protection for deep neural networks (DNNs) is an urgent need for AI corporations. To trace illegally distributed model copies, DNN watermarking is an emerging technique for embedding and verifying secret identity messages in the prediction behaviors or the model internals. Sacrificing less functionality and involving more knowledge about the target DNN, the latter branch called extit{white-box DNN watermarking} is believed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts in both the academy and the industry. In this paper, we present the first systematic study on how the mainstream white-box DNN watermarks are commonly vulnerable to neural structural obfuscation with extit{dummy neurons}, a group of neurons which can be added to a target model but leave the model behavior invariant. Devising a comprehensive framework to automatically generate and inject dummy neurons with high stealthiness, our novel attack intensively modifies the architecture of the target model to inhibit the success of watermark verification. With extensive evaluation, our work for the first time shows that nine published watermarking schemes require amendments to their verification procedures.
研究の動機と目的
- 主流のホワイトボックスDNNウォーターマーク検証がニューラル構造的不透明化に対して脆弱であることを強調する。
- 生成と注入のプリミティブを備えた包括的なダミーニューロン攻撃フレームワークを提案する。
- モデル有用性を維持したまま九つの公開ウォーターマーク方式に対する攻撃の有効性を示す。
提案手法
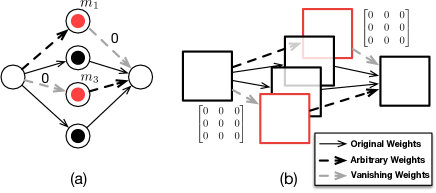
- モデル出力を不変に保ちながらウォーターマーク検証を変更するダミーニューロンを導入する。
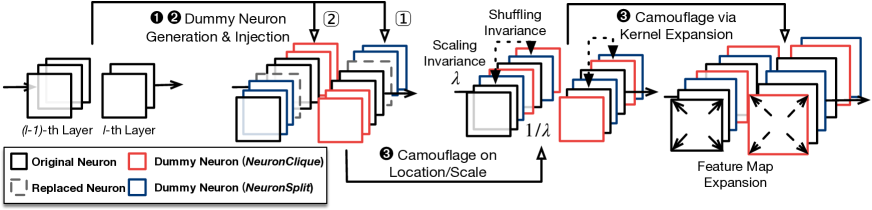
- 非消失重みを持つダミーニューロン群を作成するためのプリミティブとしてNeuronCliqueとNeuronSplitを開発する。
- カモフラージュの考慮をもって背面から前方へダミーニューロンを注入し、スケーリング/シャッフリング不変性を活用する。
- カモフラージュされたモデルを作成するためにカーネル拡張と重み分布の工夫を適用する。
- ダミーニューロン除去アプローチを含む防御志向の議論を提供する。
実験結果
リサーチクエスチョン
- RQ1主流のホワイトボックスウォーターマーク検証を、有用性の喪失やデータアクセスなしに信頼性高く撹乱できるか。
- RQ2非消失重みを持つダミーニューロンは、多様な方式に対してウォーターマーク検証を効果的に無効化するか。
- RQ3モデル機能を維持しつつ、ダミーニューロンを自動生成・ステルスに注入できるか。
- RQ4このようなニューラル構造的不透明化とウォーターマーク除去に対する防御は何か。
主な発見
- 九つの公開ホワイトボックスウォーターマーク方式は攻撃後に検証に成功せず、検証はランダムに低下する。
- 不透明化後も通常のモデル有用性は変わらない。
- 攻撃フレームワークはNeuronCliqueとNeuronSplitプリミティブを用いてダミーニューロンを自動生成・注入する。
- スケーリング、シャッフリング、カーネル拡張技術を用いたステルス性の向上。
- 本論は防御側の知識要件を議論し、ダミーニューロン除去アルゴリズムを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。