[論文レビュー] Revisiting Feature Prediction for Learning Visual Representations from Video
この論文は V-JEPA を紹介します。2M 本の動画に対してのみ特徴予測目的で事前学習された視覚モデルのファミリーで、凍結されたバックボーンと短い事前学習で強力なモーションおよび外観表現を達成します。
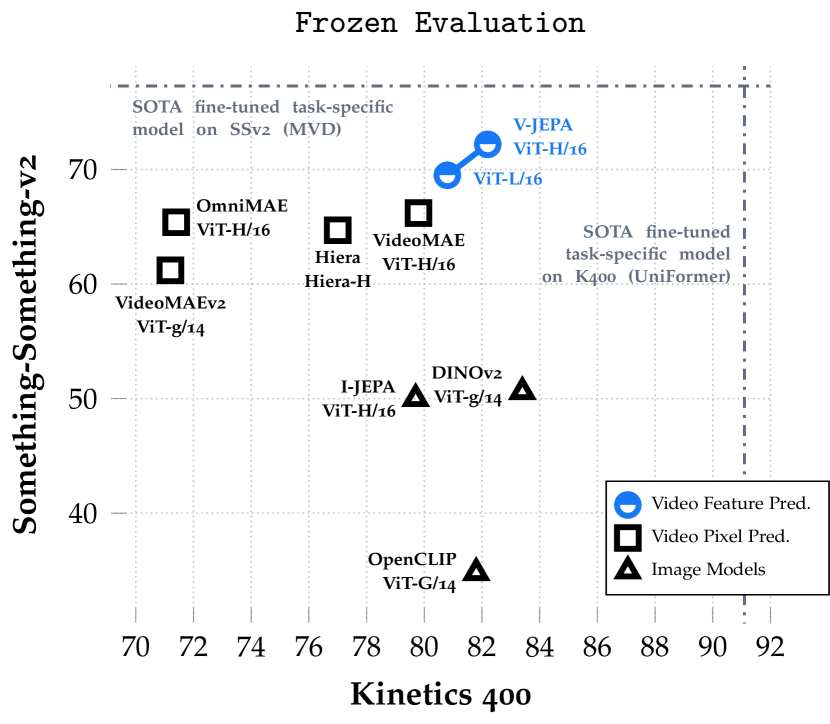
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
研究の動機と目的
- スタンドアロンの特徴予測目的を用いて、動画からの教師なしビジュアル表現学習を動機づける。
- 事前学習済みエンコーダやピクセル再構成を用いず、ソース表現からターゲット表現を予測する JEPA ベースのフレームワークを開発する。
- 凍結およびファインチューニング設定の下で、特徴予測事前学習が下流の画像および動画タスクへどの程度転移するかを評価する。
- 動画ベースの表現学習における性能に影響を与える設計選択(マスキング、データ分布、プーリング)を分析する。
提案手法
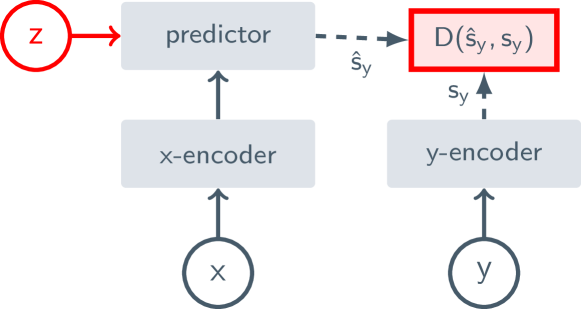
- ビデオ入力内で x から y を予測することによって学習する、結合埋め込み予測アーキテクチャ(JEPA)を採用する。
- x を動画のマスクされた部分集合とし、y は補集合のターゲットとするマスクド特徴予測タスクを用い、L1 損失とストップ勾配/EMA 崩壊防止で訓練する。
- x と y を ViT ベースのエンコーダと、マスク付きトークン列上で動作する学習可能なマスクトークンを用いる軽量プレディクタで表現する。
- 大きな連続した時空領域をマスクする多ブロックマスキング戦略を採用し、挑戦的な予測タスクを作成する。
- 注意機構付きプロービング、適応プーリング、およびエンドツーエンドのファインチューニングで評価し、凍結時とファインチューニング時の両方の性能を評価する。)
実験結果
リサーチクエスチョン
- RQ1スタンドアローンの目的としての特徴予測は、動画からの視覚表現の教師なし学習としてどれほど有効か?
- RQ2動画ベースの特徴予測は、モデルの重みを変更せずにモーションベースと外観ベースの下流タスクへ適切に転移する表現を生み出せるか?
- RQ3どの設計選択(マスキング戦略、データ混合、プーリング)が、動画から学習した表現の質に最も影響を与えるか?
主な発見
- V-JEPA を用いた特徴予測は、凍結されたバックボーンを使用して、モーションベースのタスク(Something-Something-v2)と外観ベースのタスク(Kinetics-400)で良好に機能する多用途な表現を生み出す。
- 特徴予測事前学習は凍結評価時にピクセル予測ベースラインを上回り、ファインチューニング時には競合的で、事前学習期間が短い。
- クロスアテンションによる適応型プーリングは、単純な平均プーリングより下流の性能を大幅に向上させる(特に K400 と SSv2 で顕著)
- 事前学習データサイズの増加は平均的な下流性能を向上させ、タスク別に最適化されたデータ混合(VideoMix2M が一般に最良の平均値を提供)でタスク特異的な最高結果を達成する。
- V-JEPA はラベル効率が高く、ラベルデータが少ない regimes でピクセル予測ベースラインとの差が大きくなる。
- ピクセル予測ビデオモデルと比較して、V-JEPA は競争力のあるまたは上回る性能を発揮し、事前学習サンプル数と計算資源を少なくて済ませる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。