[論文レビュー] Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
本論文は、複数のモデルファミリ、タスク、微調整スキームに渡るメモリ効率的な大規模言語モデル微調整のためのゼロ次(BPなし)最適化法をベンチマークし、改善案を提案する。
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow {in size}, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by MeZO. Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, first-of-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM .
研究の動機と目的
- 第一階の手法と比較した LLM 微調整における BPなしのゼロ次最適化のメモリ効率と精度を評価する。
- 5つの LLM ファミリと3つのタスク難易度に渡って6つのZO最適化手法をベンチマークする。
- ZO性能に影響を与える最適化原理とタスク整合性要因を特定する。
- メモリ効率と精度を向上させるZO手法の強化案(ブロック単位、ZO/FOのハイブリッド、スパース性)を提案する。
提案手法
- LLM微調整に適用可能なゼロ次最適化手法をレビューし分類する(ZO-SGD、ZO-SGD-Sign、ZO-SGD-MMT、ZO-SGD-Cons、ZO-Adam、Forward-Grad)。
- FO勾配を近似するために方向微分解釈を用いた乱択勾配推定器(RGE)を使用する。
- 微調整タスクを事前学習目的と整合させるプロンプトを比較することでタスク整合性を調査する。
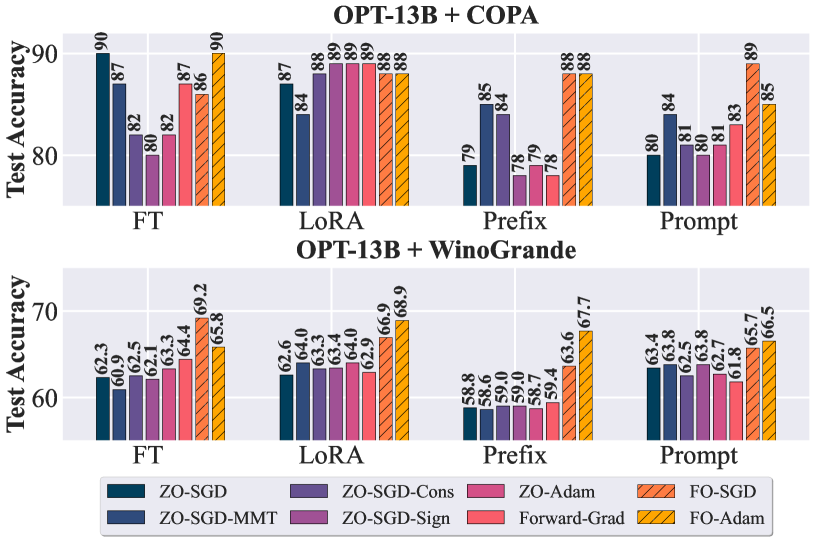
- Roberta-Large、OPT、LLaMA2、Vicuna、Mistral の5つのファミリ、3つのタスク難易度(SST2、COPA、WinoGrande)および5つの微調整方式(FT、LoRA、Prefix、Prompt など)で大規模ベンチマークを実施する。
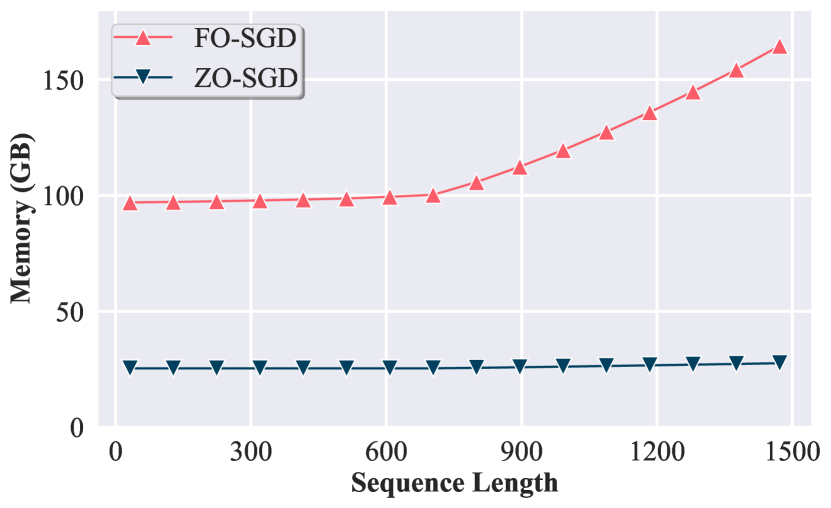
- BPなしとFO法を比較するために、1反復あたりのメモリ、GPU使用量、実行時間を評価する。
- 強化案を探る:ブロック単位ZO、ZO/FOハイブリッド訓練、スパース性誘導のZO勾配推定。
実験結果
リサーチクエスチョン
- RQ1包括的なベンチマークは、LLM微調整におけるゼロ次最適化の精度とメモリ効率のトレードオフを明らかにできるか。
- RQ2タスク整合性、フォワード勾配、アルゴリズムの複雑さは、モデル規模を超えてZOベースの微調整性能にどう影響するか。
- RQ3ブロック単位最適化、ハイブリッドZO/FO、勾配のスパース性などの強化は、メモリ利得を維持しつつZO微調整を改善するか。
- RQ4PEFTスキームとモデルファミリ全体で、ZO手法とForward-GradおよびFO最適化器の相対的な性能はどうか。
主な発見
- ZO最適化は一部の設定で競争力のある結果を達成できるが、モデルやタスク間で高いばらつきを示す。
- Forward-Gradはクエリ予算が十分な場合、多くのZO手法を上回るが、より大きなモデルや混合精度トレーニングと互換性がない場合、メモリ効率の利点は薄れる。
- ZO-SGD-ConsとZO-SGD-MMTは複数の設定で安定した性能を示す一方、ZO-SGD-Signは単純なプロンプトを除きしばしばパフォーマンスが劣る。
- Prompt-based task alignment significantly impacts ZO performance; without alignment, ZO methods suffer notable accuracy drops.
- LoRA-based fine-tuning shows robustness across various ZO methods, suggesting compatibility with memory-efficient training strategies.
- On larger models and more complex tasks, FO methods generally outperform ZO methods by a noticeable margin, highlighting scalability limits of ZO approaches.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。