[論文レビュー] Reward Design with Language Models
この論文は、自然言語プロンプトからRLエージェントを訓練する代理報酬関数として大規模言語モデルを使用することを提案し、ユーザー目標の少数ショットまたはゼロショットの指定を可能にし、Ultimatum Game、Matrix Games、DealOrNoDeal の交渉で競争力のある整合性を実証する。
Reward design in reinforcement learning (RL) is challenging since specifying human notions of desired behavior may be difficult via reward functions or require many expert demonstrations. Can we instead cheaply design rewards using a natural language interface? This paper explores how to simplify reward design by prompting a large language model (LLM) such as GPT-3 as a proxy reward function, where the user provides a textual prompt containing a few examples (few-shot) or a description (zero-shot) of the desired behavior. Our approach leverages this proxy reward function in an RL framework. Specifically, users specify a prompt once at the beginning of training. During training, the LLM evaluates an RL agent's behavior against the desired behavior described by the prompt and outputs a corresponding reward signal. The RL agent then uses this reward to update its behavior. We evaluate whether our approach can train agents aligned with user objectives in the Ultimatum Game, matrix games, and the DealOrNoDeal negotiation task. In all three tasks, we show that RL agents trained with our framework are well-aligned with the user's objectives and outperform RL agents trained with reward functions learned via supervised learning
研究の動機と目的
- 手作りの報酬やラベル付きデータを超える、より直感的な報酬指定を可能にする動機づけ。
- RLアルゴリズムの変更を伴わずに、LLMを代理報酬関数として使用する一般的なRLフレームワークを提案する。
- LLMベースの報酬が、SLで学習した報酬よりもユーザー目標とエージェントの整合を改善できることを示す。
- 複数の対話タスクにおいて、単発および複数ショットのプロンプト適用で方法を評価する。
提案手法
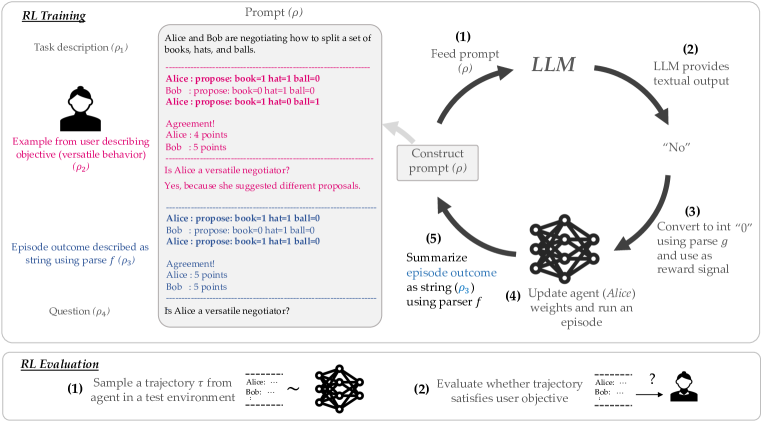
- タスクプロンプトとエピソード記述を与えられたときに報酬を生み出すLLMを用いて、報酬をどのように生成するかを、報酬を出力するMDPとして形式化する。
- タスク説明、ユーザーが指定した目的(例示または説明)、エピソード結果、目的の達成度に関する質問を連結してrhoというプロンプトを構築する。
- LLM出力をタスク固有のパーサーgで解析して、RL更新のためのスカラー報酬を得る。
- LLM由来の報酬を用いて、任意のRLアルゴリズムでRLエージェントを訓練する。
- LLM報酬信号のラベリング精度と、下流のRLエージェントのパフォーマンスを真の報酬と比較して評価する。
- パイロットとしてのユーザ調査を実施し、ユーザー目標との主観的整合性を評価する。
実験結果
リサーチクエスチョン
- RQ1Q1: 少数ショットプロンプティングから、LLMsはユーザー目標と一致した報酬信号を生み出せるか。
- RQ2Q2: ゼロショットプロンプティングで、よく知られた目的に対して目的に一貫した報酬をLLMsは生み出せるか。
- RQ3Q3: 長期的な交渉のようなタスクでも、目的に整合した報酬をLLMsは提供できるか。
主な発見
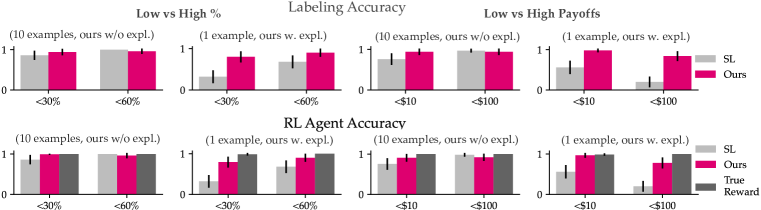
- LLMsは少数ショットのプロンプトからユーザー目標と一致した報酬信号を提供し、説明が精度を大幅に補助する。
- マトリックスゲームでは、ゼロショットプロンプトでよく知られた概念に対して目的に沿った報酬を生み出し、No Objectiveベースラインよりラベリング精度を向上させる。
- DealOrNoDeal では、LLMベースの報酬がRLエージェントの精度を平均で46%向上させ、真の報酬パフォーマンスに4%程度迫る。
- パイロットのユーザ調査は、ユーザーが指定したスタイルにエージェントが整合する場合に、著しく高い整合性を示した(p<0.001)。
- SLベースラインと比較して、LLM報酬はデータ効率が高い。SLは同等の精度に達するために何百ものラベル付き例を追加で必要とする。
- プロンプト設計の頑健性分析では、説明が高精度の要因であり、語彙の変化に対してプロンプトは比較的頑健である可能性が示唤された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。