[論文レビュー] ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
ReWOO は推論をツール観察から分離し、拡張言語モデルのトークン使用を劇的に削減しつつ、複数段階のNLPタスクで精度を維持または向上させ、より小さなモデルへの推論の特化を可能にする。
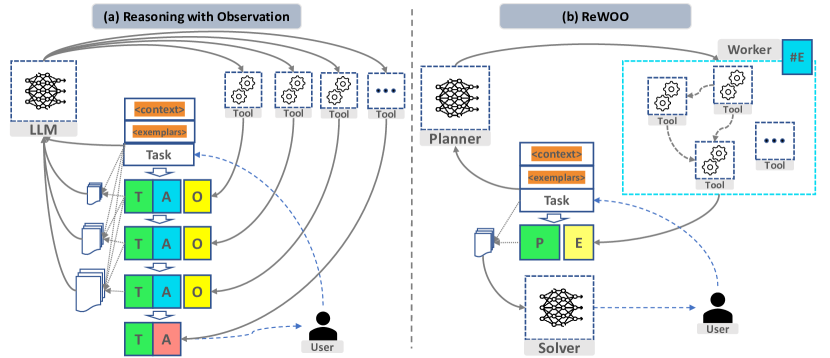
Augmented Language Models (ALMs) blend the reasoning capabilities of Large Language Models (LLMs) with tools that allow for knowledge retrieval and action execution. Existing ALM systems trigger LLM thought processes while pulling observations from these tools in an interleaved fashion. Specifically, an LLM reasons to call an external tool, gets halted to fetch the tool's response, and then decides the next action based on all preceding response tokens. Such a paradigm, though straightforward and easy to implement, often leads to huge computation complexity from redundant prompts and repeated execution. This study addresses such challenges for the first time, proposing a modular paradigm ReWOO (Reasoning WithOut Observation) that detaches the reasoning process from external observations, thus significantly reducing token consumption. Comprehensive evaluations across six public NLP benchmarks and a curated dataset reveal consistent performance enhancements with our proposed methodology. Notably, ReWOO achieves 5x token efficiency and 4% accuracy improvement on HotpotQA, a multi-step reasoning benchmark. Furthermore, ReWOO demonstrates robustness under tool-failure scenarios. Beyond prompt efficiency, decoupling parametric modules from non-parametric tool calls enables instruction fine-tuning to offload LLMs into smaller language models, thus substantially reducing model parameters. Our illustrative work offloads reasoning ability from 175B GPT3.5 into 7B LLaMA, demonstrating the significant potential for truly efficient and scalable ALM systems.
研究の動機と目的
- ツールで拡張LLMワークフローにおけるトークンの冗長性を削減する動機づけとして、観察から推論を分離する。
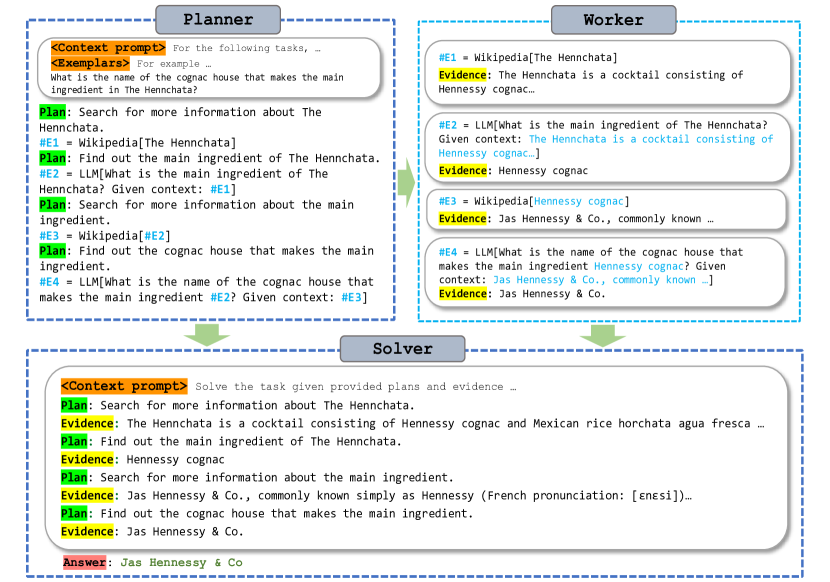
- 推論とツールフィードバックを切り離すモジュラーな Planner-Worker-Solver フレームワーク(ReWOO)を提案する。
- 多様なベンチマークでトークン効率の向上と精度の改善を定量化する。
- ツール障害に対するロバスト性を実証し、推論をより小さなモデルへ specialization を通してオフロードする潜在性を示す。
提案手法
- Planner-Worker-Solver アーキテクチャを導入し、推論、ツール呼び出し、エビデンス合成を分離する。
- 観察依存 prompting と比較してトークン使用量を削減する形式的プロンプト-token 分析を提供する。
- ツール応答前の計画を可能にする exemplars と多様なツールセットを用いる。
- instruction tuning を介して予測可能な推論を小型 LLMS(Planner 7B)へオフロードすることで specialisation を活用する。
- 複数のベンチマーク(HotpotQA、TriviaQA、GSM8K、StrategyQA、PhysicsQA、SportsUnderstanding、SOTUQA)とベースラインとして GPT-3.5-turbo を用いて評価する。
実験結果
リサーチクエスチョン
- RQ1観察から推論を分離することで、ALM のトークンコストを精度を犠牲にせずに削減できるか?
- RQ2ReWOO は multi-step NLP タスクにおいて ReAct および直接 prompting と比較してどの程度の性能を示すか?
- RQ3既知の推論を smaller model へ specialization によりどの程度オフロードできるか?
- RQ4ツール障害や余分なツールに対して ReWOO はどの程度ロバストか?
- RQ5このパラダイムにおける会話 RLHF の影響はどの程度あるか?
主な発見
- ReWOO は 6 つの NLP ベンチマーク全体で平均してトークン使用量を 64% 削減した。
- ReWOO は ReAct に対して平均で絶対精度を 4.4 ポイント改善した。
- SOTUQA では、ReWOO は ReAct よりも絶対精度が 8% 高く、トークンを 43%節約している。
- ツール障害シナリオでのロバスト性を維持し、ツール障害時に ReAct より劣化が小さい。
- specialisation により 7B の LLaMA ベースの Planner が、複数のベンチマークで 25× 大きい GPT-3.5 の性能に匹敵できる可能性がある。
- ベンチマーク全体で、ReWOO は一貫した性能を示しつつ prompting コストを大幅に削減する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。