[論文レビュー] RF-DETR Object Detection vs YOLOv12 : A Study of Transformer-based and CNN-based Architectures for Single-Class and Multi-Class Greenfruit Detection in Complex Orchard Environments Under Label Ambiguity
この研究は、複雑な果樹園における緑果検出のため、RF-DETR(トランスフォーマーベース)とYOLOv12(CNNベース)を直接比較し、ラベル曖昧性の下で単一クラスおよびマルチクラス(遮蔽あり vs 遮蔽なし)シナリオを評価します。RF-DETRは精度で優位を占め、YOLOv12はエッジ推定の効率性を提供します。
This study conducts a detailed comparison of RF-DETR object detection base model and YOLOv12 object detection model configurations for detecting greenfruits in a complex orchard environment marked by label ambiguity, occlusions, and background blending. A custom dataset was developed featuring both single-class (greenfruit) and multi-class (occluded and non-occluded greenfruits) annotations to assess model performance under dynamic real-world conditions. RF-DETR object detection model, utilizing a DINOv2 backbone and deformable attention, excelled in global context modeling, effectively identifying partially occluded or ambiguous greenfruits. In contrast, YOLOv12 leveraged CNN-based attention for enhanced local feature extraction, optimizing it for computational efficiency and edge deployment. RF-DETR achieved the highest mean Average Precision (mAP50) of 0.9464 in single-class detection, proving its superior ability to localize greenfruits in cluttered scenes. Although YOLOv12N recorded the highest mAP@50:95 of 0.7620, RF-DETR consistently outperformed in complex spatial scenarios. For multi-class detection, RF-DETR led with an mAP@50 of 0.8298, showing its capability to differentiate between occluded and non-occluded fruits, while YOLOv12L scored highest in mAP@50:95 with 0.6622, indicating better classification in detailed occlusion contexts. Training dynamics analysis highlighted RF-DETR's swift convergence, particularly in single-class settings where it plateaued within 10 epochs, demonstrating the efficiency of transformer-based architectures in adapting to dynamic visual data. These findings validate RF-DETR's effectiveness for precision agricultural applications, with YOLOv12 suited for fast-response scenarios. >Index Terms: RF-DETR object detection, YOLOv12, YOLOv13, YOLOv14, YOLOv15, YOLOE, YOLO World, YOLO, You Only Look Once, Roboflow, Detection Transformers, CNNs
研究の動機と目的
- RF-DETRとYOLOv12のカスタム緑果データセットにおける単一クラスおよびマルチクラスラベルでの検出精度を評価する。
- 実際の果樹園条件での遮蔽、偽装、背景雑音に対するモデル性能を評価する。
- 収束挙動と推論効率を分析し、精密農業での展開方針を導く。
提案手法
- RF-DETRとYOLOv12に同一データセット、トレーニングプロトコル、エポック数を適用する。
- DINOv2バックボーンと変形アテンションを備えたRF-DETR;アンカーBoxやNMSなし;単一スケール特徴。
- R-ELANバックボーンとエリアアテンションを備えたYOLOv12;検出、向き境界ボックス、インスタンスセグメンテーションのマルチタスクヘッド。
- 入力解像度を640x640に標準化;FP32でバッチサイズ約16、RTX A5000で学習。
- 精度、リコール、F1、mAP@50およびmAP@50:95、mIoUを用いて評価;推論速度を評価。
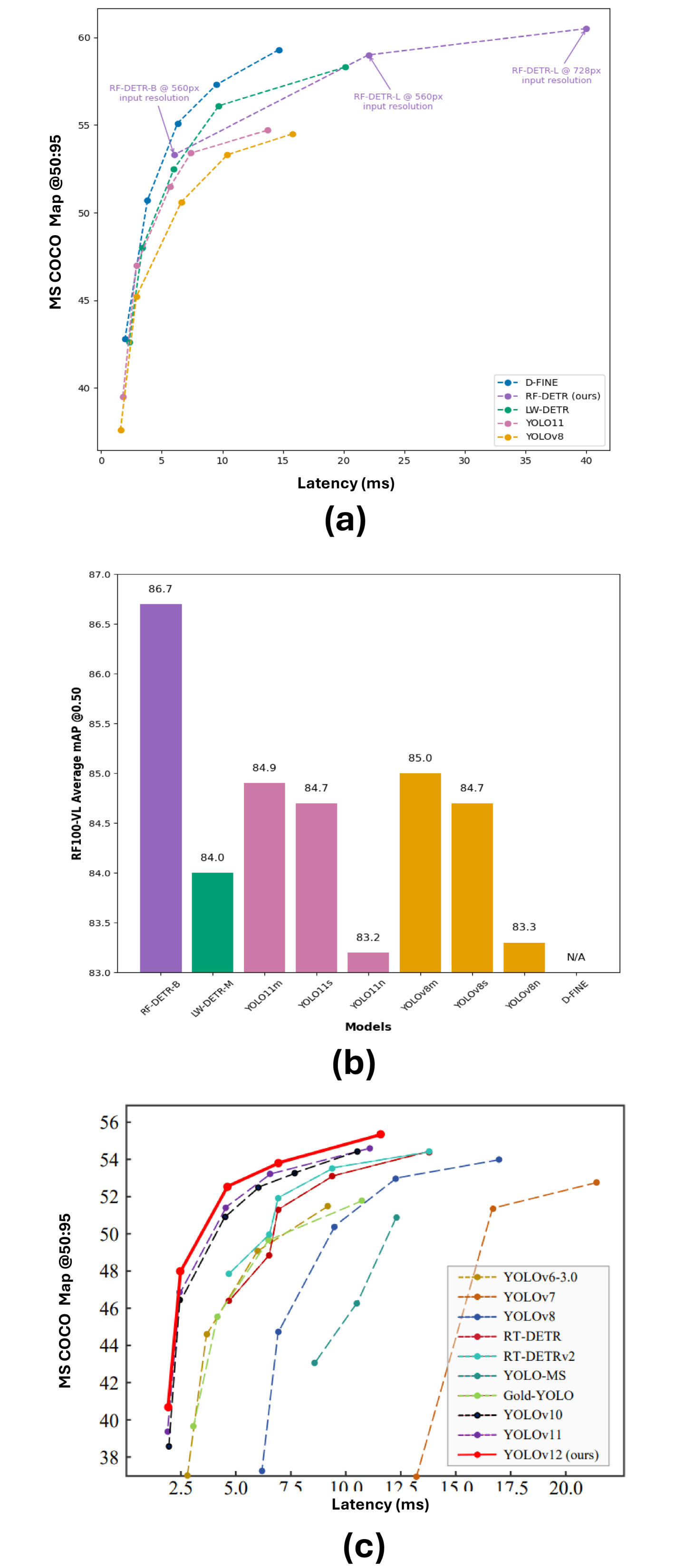
実験結果
リサーチクエスチョン
- RQ1ラベル曖昧性の下で単一クラス緑果検出におけるRF-DETRとYOLOv12の比較はどうなるか。
- RQ2遮蔽あり vs 遮蔽なしの果実を区別するマルチクラス検出において、両モデルはどのように性能を発揮するか。
- RQ3この農業コンテキストにおけるトランスフォーマーベースとCNNベース検出器の収束ダイナミクスとトレーニング効率はどうか。
- RQ4RF-DETRとYOLOv12の推論速度とエッジ展開適合性はどの程度か。
主な発見
- RF-DETRは単一クラス検出でmAP@50が0.9464を達成。
- YOLOv12Nは単一クラスシナリオでmAP@50:95が0.7620で最高。
- マルチクラス検出ではRF-DETRがmAP@50で0.8298を達成。
- YOLOv12Lはマルチクラス条件でmAP@50:95が0.6622をリード。
- RF-DETRは急速に収束し、タスクに応じて10-20エポック未満でプラトーに達するなど、効率的なトレーニングダイナミクスを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。