[論文レビュー] RiNALMo: General-Purpose RNA Language Models Can Generalize Well on Structure Prediction Tasks
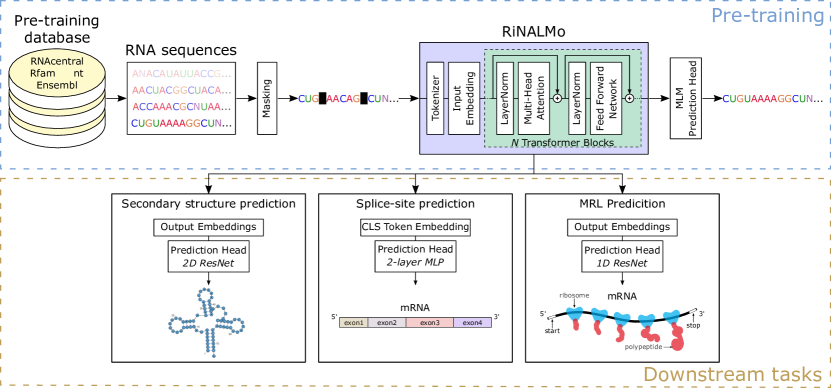
RiNALMo は 36M の ncRNA 配列で事前学習された 650M パラメータの RNA 言語モデルで、RNA 構造と機能タスクへの一般化能力を示し、 unseen RNA families を含む複数のデータセットで既存モデルを上回る。
While RNA has recently been recognized as an interesting small-molecule drug target, many challenges remain to be addressed before we take full advantage of it. This emphasizes the necessity to improve our understanding of its structures and functions. Over the years, sequencing technologies have produced an enormous amount of unlabeled RNA data, which hides a huge potential. Motivated by the successes of protein language models, we introduce RiboNucleic Acid Language Model (RiNALMo) to unveil the hidden code of RNA. RiNALMo is the largest RNA language model to date, with 650M parameters pre-trained on 36M non-coding RNA sequences from several databases. It can extract hidden knowledge and capture the underlying structure information implicitly embedded within the RNA sequences. RiNALMo achieves state-of-the-art results on several downstream tasks. Notably, we show that its generalization capabilities overcome the inability of other deep learning methods for secondary structure prediction to generalize on unseen RNA families.
研究の動機と目的
- 大規模なラベルなしRNAデータを活用して一般目的のRNA表現を学習する。
- 現代的なアーキテクチャ改善を取り入れたRNA専用のTransformerエンコーダを事前学習する。
- RiNALMo を多様な下流タスクで評価し、構造と機能の一般化を測る。
- 未知のRNAファミリを評価する際の世代間一般化を実証する。
- より広範な普及と再現性を可能にするコードの公開を提供する。
提案手法
- RiNALMo(650Mパラメータ)をBERT風エンコーダとして、RNAcentral・Rfam・nt・Ensembl 由来の36M ncRNA 配列のマスク付き言語モデリングで事前学習する。
- RoPE位置エンコーディング、SwiGLU活性化、FlashAttention-2、ブロックあたり20のアテンションヘッドを用いて33のTransformerブロックを使用する。
- 入力長を1024トークンに制限し、15% の破損(80% マスク、10% ランダムトークン、10% 変更なし)でクロスエントロピー損失を用いて学習する。
- シーケンスを1280次元の埋め込み表現で表現し、CLSを先頭に、EOSを末尾に付与する;下流タスクにはエンドツーエンドで微調整し、単純な予測ヘッドを付ける。
- 学習済み埋め込みを、構造タスクには単純なResNetベースの予測器を接続し、スプライスサイト・リボソームロードタスクにはMLPヘッドを用いて評価する。
実験結果
リサーチクエスチョン
- RQ1RiNALMo は訓練中に見られなかったRNAファミリへ一般化して二次構造予測を行えるか。
- RQ2既存のRNA LMや従来法と比較して、マルチ種間のスプライスサイト予測でどのように性能を示すか。
- RQ3RiNALMo は平均リボソームロード予測で正確性を発揮し、ランダム起源の訓練から人間配列へ一般化できるか。
主な発見
- RiNALMo はファミリ間の二次構造予測で他の方法を大きく上回り、ほとんどのファミリでF1スコアが高い。
- ファミリ間の一般化において、RiNALMo は9ファミリ中8ファミリで熱力学ベースおよび深層学習ベースのベースラインを上回る(テロメラーゼRNAは例外)。
- マルチ種間スプライスサイト予測で、RiNALMo は魚類・昆虫・植物・線虫のデータセットで最先端のF1スコアを達成。
- 平均リボソームロード予測で、RiNALMo は Random7600 と Human7600 の両データセットで Uni-RNA・RNA-FM・Optimus 5-Prime より高いR^2スコアを達成。
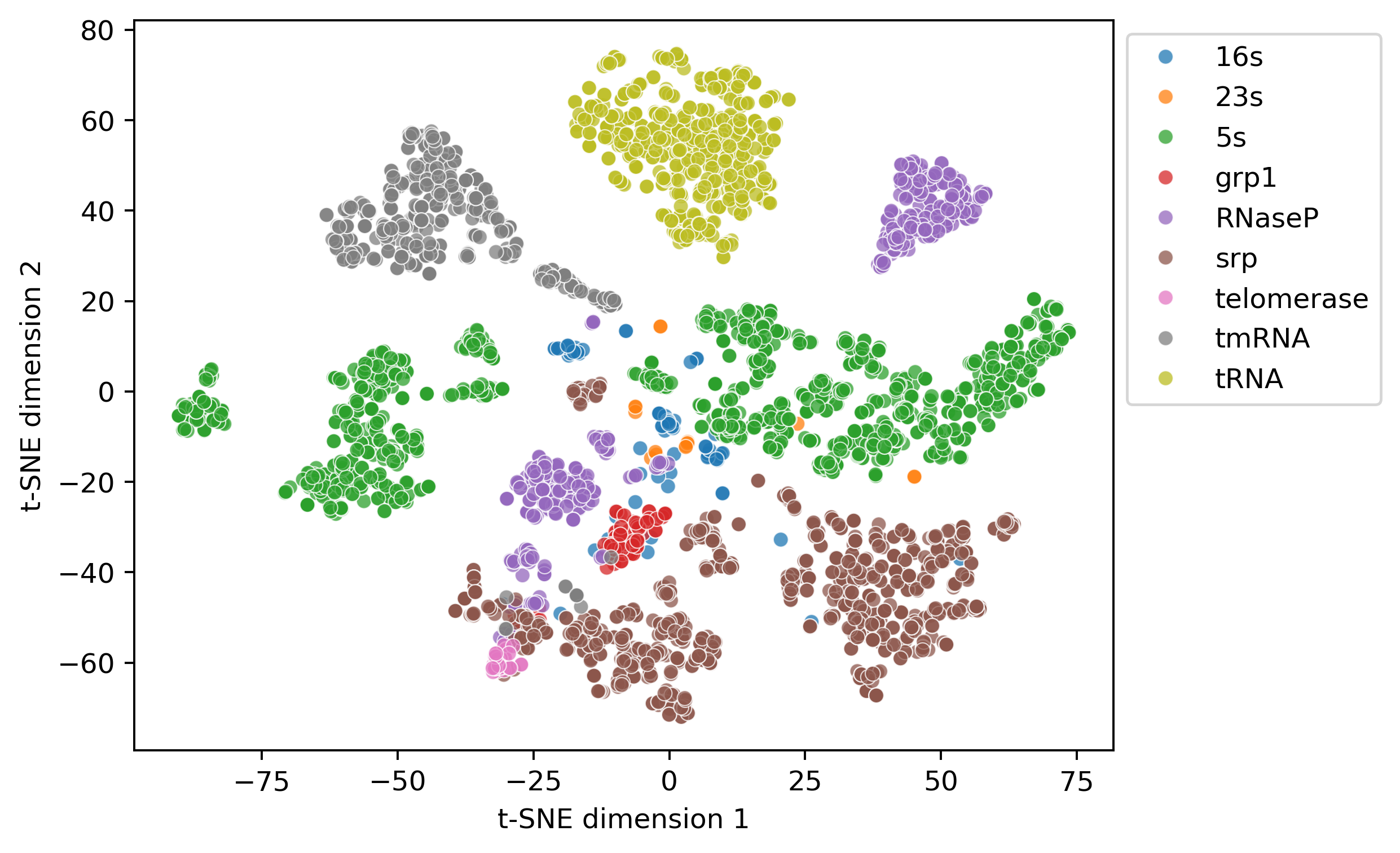
- RiNALMo のファミリ間構造埋め込みは t-SNE 可視化でRNAファミリによる明確なクラスタリングを示し、埋め込みには豊富な構造情報が含まれている。
- RiNALMo のファミリ間平均二次構造F1スコアは 0.72 で、RNAstructure (0.59) や CONTRAfold (0.61) および他のベースラインより高い(表 2)。
- ドナー/アクセプターのスプライスサイト予測で、RiNALMo は魚類97.70、昆虫類96.11、植物96.25、線虫95.63 の平均F1スコアを達成。
- RiNALMo のスプライスサイト予測は、報告された種別分割で SpliceBERT・Uni-RNA・RNA-FM・Spliceator を上回る(表 3)。
- RiNALMo はランダム起源の配列で訓練されても人間UTR MRLデータでほぼ現状性能を示すなど、強力な一般化を示している(Table 4 の Random7600 対 Human7600)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。