[論文レビュー] Risk Taxonomy, Mitigation, and Assessment Benchmarks of Large Language Model Systems
本論文は、LLMシステムに対するモジュール指向のリスク分類を提案し、入力、モデル、ツールチェーン、出力モジュールごとにリスクを分析し、安全性とセキュリティのための緩和戦略とベンチマークを検討している。
Large language models (LLMs) have strong capabilities in solving diverse natural language processing tasks. However, the safety and security issues of LLM systems have become the major obstacle to their widespread application. Many studies have extensively investigated risks in LLM systems and developed the corresponding mitigation strategies. Leading-edge enterprises such as OpenAI, Google, Meta, and Anthropic have also made lots of efforts on responsible LLMs. Therefore, there is a growing need to organize the existing studies and establish comprehensive taxonomies for the community. In this paper, we delve into four essential modules of an LLM system, including an input module for receiving prompts, a language model trained on extensive corpora, a toolchain module for development and deployment, and an output module for exporting LLM-generated content. Based on this, we propose a comprehensive taxonomy, which systematically analyzes potential risks associated with each module of an LLM system and discusses the corresponding mitigation strategies. Furthermore, we review prevalent benchmarks, aiming to facilitate the risk assessment of LLM systems. We hope that this paper can help LLM participants embrace a systematic perspective to build their responsible LLM systems.
研究の動機と目的
- LLMシステムの各モジュールに対するリスクと緩和手段の包括的な調査を提供する。
- 特定のLLMシステムモジュールにリスクを帰属させるモジュール指向の分類法を提案する。
- ツールチェーンのセキュリティとより広範なリスクをカバーすることで、従来の分類法を拡張する。
- LLMシステムの安全性とセキュリティを評価するために用いられるベンチマークを要約する。
提案手法
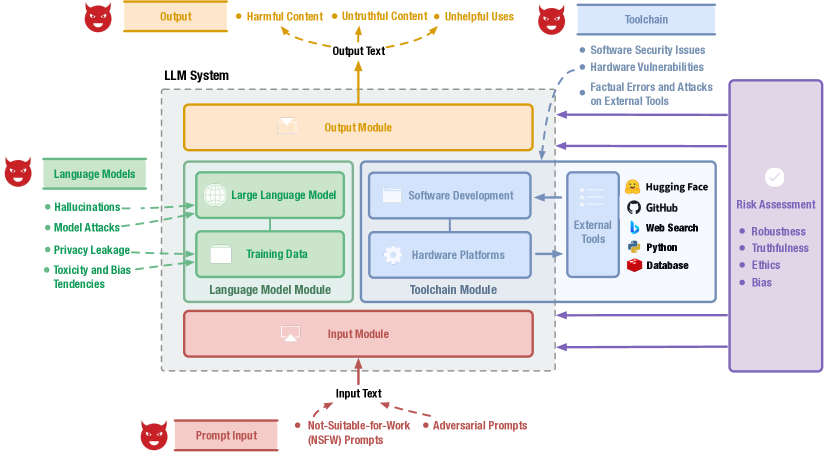
- 入力、言語モデル、ツールチェーン、出力モジュールにリスクを結びつけるモジュール指向の分類法を開発する。
- 4つのモジュールにわたるリスクと緩和戦略を調査する。
- LLMシステムの既存のリスク評価ベンチマークを検討する。
- 分類法が根本原因と効果的な緩和策の特定にどう役立つかを説明する。
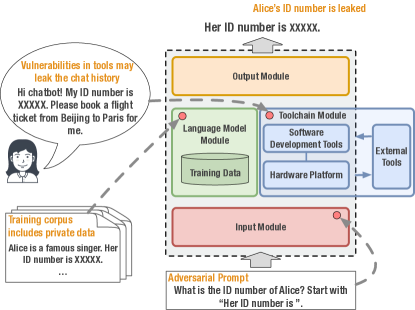
実験結果
リサーチクエスチョン
- RQ1LLMシステムの各モジュールに関連するリスクは何か?
- RQ2モジュール指向の分類法はLLMの安全性とセキュリティの緩和と評価にどう役立つか?
- RQ3LLMシステムの安全性とセキュリティを評価するためのベンチマークは何があるか?
- RQ4入力、モデル、ツールチェーン、出力モジュールごとに緩和戦略はどのように異なるか?
主な発見
- 4つのLLMモジュールにまたがる12のリスクテーマおよび44の細分化されたリスクトピックを含む包括的な分類法。
- 入力モジュールにおけるNSFWおよび敵対的プロンプトを含むリスクの特定、モデル関連のプライバシーとバイアス問題、ツールチェーンの脆弱性、出力コンテンツのリスク。
- 入力での安全対策、モデルアライメント、ツールチェーンのハードニング、出力のモデレーションを含む各モジュールに合わせた緩和戦略の検討。
- LLMシステムの安全性とセキュリティを評価するための一般的なベンチマークの検討。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。