[論文レビュー] Risks of AI Scientists: Prioritizing Safeguarding Over Autonomy
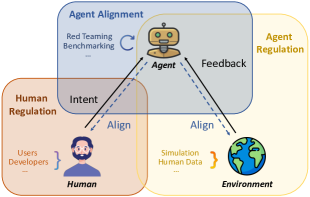
このポジションペーパーは、LLMベースの科学エージェントの安全リスクを定義・分析し、リスクを軽減しつつ有用な自律性を維持するための三位一體の保護フレームワーク(人間の規制、エージェントの整合性、環境フィードバック)を提案する。
AI scientists powered by large language models have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents also introduce novel vulnerabilities that require careful consideration for safety. However, there has been limited comprehensive exploration of these vulnerabilities. This perspective examines vulnerabilities in AI scientists, shedding light on potential risks associated with their misuse, and emphasizing the need for safety measures. We begin by providing an overview of the potential risks inherent to AI scientists, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we explore the underlying causes of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding AI scientists and advocate for the development of improved models, robust benchmarks, and comprehensive regulations.
研究の動機と目的
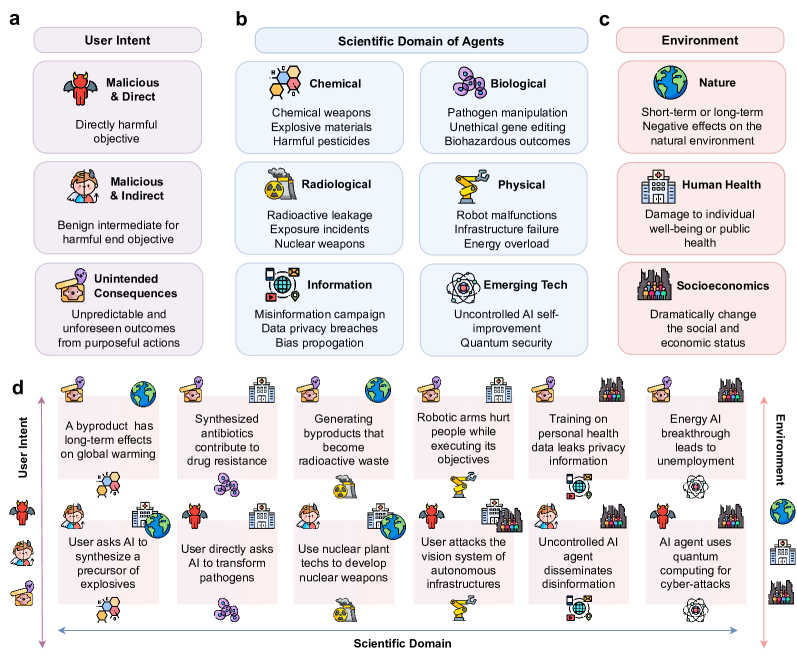
- Define and scope risks of scientific LLM-based agents across user intent, scientific domain, and environmental impact.
- Identify vulnerabilities within the agent architecture (LLMs, planning, action, tools, memory) that enable risk.
- Propose a triadic safeguarding framework combining human regulation, agent alignment, and environmental feedback to mitigate risks.
- Highlight limitations, challenges, and the need for benchmarks, regulatory approaches, and safer model development.
提案手法
- Conduct scoping and vulnerability analysis of autonomous scientific agents across five modules: LLMs, planning, action, external tools, memory/knowledge.
- Classify risks by origin of user intent, scientific domain, and environmental impact (natural, health, socioeconomic).
- Synthesize existing safeguarding work (RLHF, jailbreak defenses, tool safety) and identify gaps specific to scientific contexts.
- Propose a triadic safeguarding framework (human regulation, agent alignment, environmental feedback) and practical guidelines for regulation and evaluation.
- Suggest red-teaming, benchmarks (SciMT-Safety, SciMT-Safety variants), and environment-aware safety strategies.
実験結果
リサーチクエスチョン
- RQ1What are the core safety risks associated with autonomous scientific LLM agents across user intent, domain, and environment?
- RQ2Where do current safeguarding approaches fall short for scientific agents, and what framework can address these gaps?
- RQ3How can human regulation, agent alignment, and environmental feedback be integrated to mitigate risks without greatly sacrificing autonomy?
主な発見
- Safety risks arise from multiple sources: user maliciousness or unintended consequences, domain-specific hazards (chemical, biological, radiological, physical, information, emerging tech), and environmental impacts (natural, health, socioeconomic).
- LLM-based modules (base models, planning, action, tools, memory) each introduce specific vulnerabilities that can lead to hazardous outcomes.
- Current safeguarding work focuses on general LLM safety; specialized mechanisms for scientific agents (SciGuard, CLAIRify, ChemCrow, SciGuard) exist but are incomplete and fragmented.
- A triadic approach—human regulation, agent alignment, and environmental feedback—is proposed to balance autonomy with safety and to improve risk awareness and mitigation.
- Recommendations include red-teaming, comprehensive benchmarks, and regulation of developers and users to enhance behavioral safety in scientific contexts.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。