[論文レビュー] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
本研究は、AIフィードバックからの強化学習(RLAIF)が3つのテキスト生成タスクにおいてRLHFと同等かそれを上回ることを示しており、費用が低い場合が多く、人間の好みの整合性と同等であること、そしてAI報酬を直接使用する方法が標準の蒸留手法を上回ることを実証している。
Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences, but gathering high-quality preference labels is expensive. RL from AI Feedback (RLAIF), introduced in Bai et al., offers a promising alternative that trains the reward model (RM) on preferences generated by an off-the-shelf LLM. Across the tasks of summarization, helpful dialogue generation, and harmless dialogue generation, we show that RLAIF achieves comparable performance to RLHF. Furthermore, we take a step towards "self-improvement" by demonstrating that RLAIF can outperform a supervised fine-tuned baseline even when the AI labeler is the same size as the policy, or even the exact same checkpoint as the initial policy. Finally, we introduce direct-RLAIF (d-RLAIF) - a technique that circumvents RM training by obtaining rewards directly from an off-the-shelf LLM during RL, which achieves superior performance to canonical RLAIF. Our results suggest that RLAIF can achieve performance on-par with using human feedback, offering a potential solution to the scalability limitations of RLHF.
研究の動機と目的
- AI生成の好みラベルが、言語モデルのRLHFのための人間ラベルの代替になり得ることを実証する。
- RLAIFを要約、役に立つ対話、無害な対話タスクで、RLHFおよびSFTベースラインと比較して評価する。
- AIラベリング手法(CoT、前置き、プロンプトスタイル)が人間の好みへの整合性にどう影響するかを探る。
- AIラベラーがポリシーと同じサイズであり得るか、そしてAI報酬を直接使用することがRLの性能を改善するかを調べる。
提案手法
- 各タスクの出力候補間のペアワイズ好みをスコアリングするため、PaLM 2を既製のAIラベラーとして使用する。
- AI生成の好みに基づく報酬モデルを訓練(蒸留RLAIF)し、RM提供報酬を用いたREINFORCEベースのRLを実行する。
- 報酬モデルを介さずに、LLMが直接出力をスコアリングしてRL報酬を得る直接RLAIFと比較する。
- 人間の好みへの整合性を最大化するため、ベース/詳細な前置き、連鎖思考推論、文脈内のサンプル等のプロンプトの変 variationsを実験する。
- AIラベラーの整合性、(人間の好みに対する)勝率、無害性率を用いて整合性を評価する。
- 同じサイズのAIラベラー(AIラベラーサイズ = ポリシーサイズ)と直接AI報酬での頑健性を検証する。
- LLMサイズがAIラベリング品質と整合性に与える影響を分析する。
実験結果
リサーチクエスチョン
- RQ1AI生成の好みは、要約と対話タスクにおけるRLHF風の訓練で人間の好みと同等の性能を発揮できるか。
- RQ2RLAIFはRLHFと比較して人間の整合性品質を犠牲にすることなく、スケーラビリティとコスト面の利点を提供できるか。
- RQ3RL中に報酬としてAIの好みを蒸留して別の報酬モデルへ渡す手法よりも、直接LLMsを prompting して報酬を得る方が有効か。
- RQ4プロンプト技法とAIラベラーのサイズは人間の好みへの整合性と下流のポリシー品質にどう影響するか。
主な発見
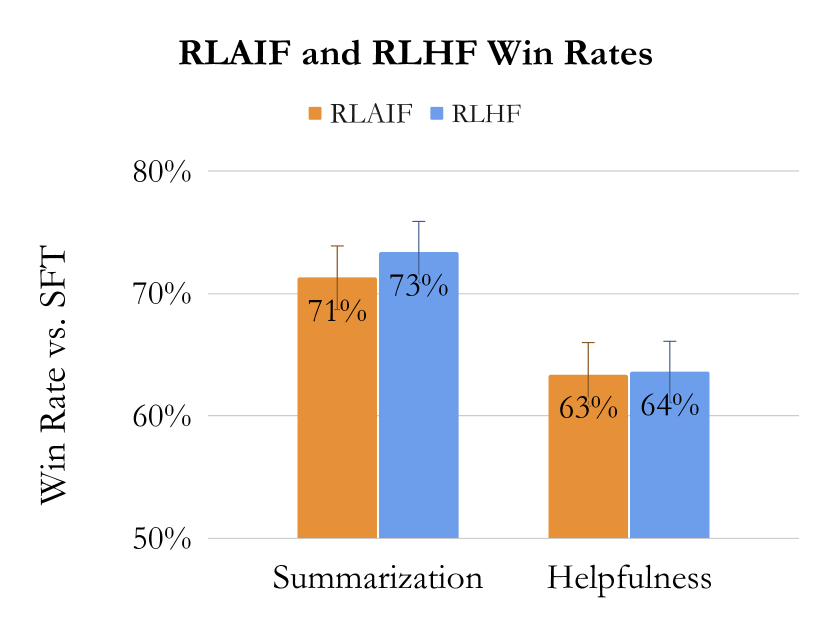
| Model comparison | Summarization win rate vs SFT (%) | Helpful dialogue win rate vs SFT (%) | Harmless rate (%) |
|---|---|---|---|
| RLAIF vs SFT | 71 | 63 | - |
| RLHF vs SFT | 73 | 64 | - |
| RLAIF vs RLHF | 50 | 52 | - |
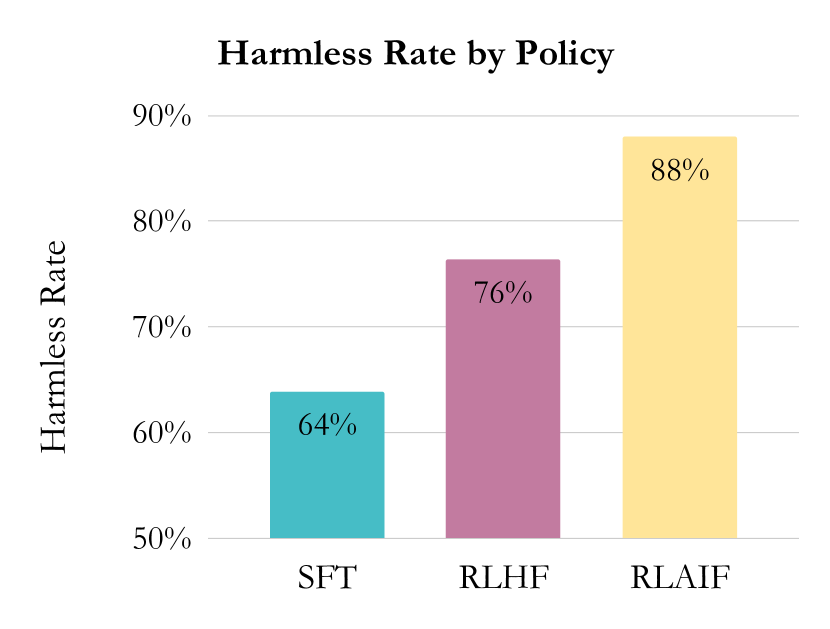
| Harmless dialogue: RLAIF vs RLHF vs SFT | - | - | 88 (RLAIF) / 76 (RLHF) / 64 (SFT) |
- RLAIFは3つのタスク(要約、役に立つ対話、無害な対話)全てでRLHFと同等または優れている。
- 要約と役に立つ対話では、RLAIFとRLHFの両方がSFTベースラインを上回る。勝率はRLAIFとRLHFで統計的に有意差なし。
- 無害な対話では、RLAIFは88%の無害率を達成し、RLHF(76%)およびSFT(64%)を上回る。
- 報酬モデルを蒸留したAI好みから得るのではなく、RL中にLLMを直接報酬へプロンプトする方法は、標準的なRLAIF設定を上回ることがある。
- AIラベラーがポリシーと同じサイズでも、RLAIFはSFTを上回ることができる。
- 思考過程を引き出すプロンプトなど、 prompting 技術はAIラベラーの整合性を一般的に改善する;詳細な前置きと少数ショット prompting はタスクによって効果が異なる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。