[論文レビュー] RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
RLEFは実行フィードバックを活用して複数ターンのコード生成LLMを強化学習で訓練し、CodeContestsで最先端の解法率を達成し、サンプル数を減らし、HumanEval+とMBPP+へ恩恵を波及させる。
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve the desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new state-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
研究の動機と目的
- 環境フィードバックを用いたコード生成LLMの基盤づくりを動機づけ、反復的修正と最終的正確性を向上させる。
- コード実行からの報酬を用いるエンドツーエンドRLフレームワーク(RLEF)を提案する。
- RLEFが小規模モデル・少数サンプルでも競技プログラミングベンチマークの解法率を改善することを示す。
- RLEFの改善を他のコード生成ベンチマーク(HumanEval+、MBPP+)およびより高いターン予算へ一般化できることを示す。
提案手法
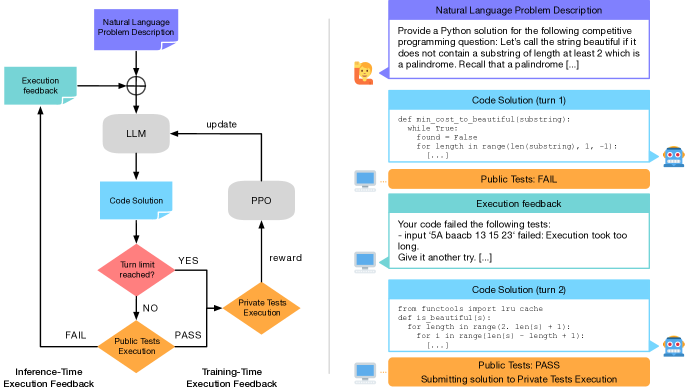
- 各ターンでコードを生成し実行フィードバックを受け取る、マルチターン対話として反復的コード合成をモデル化する。
- トレーニング時には公開セットをフィードバック用、非公開セットを最終評価用として用い、リークを避けて堅牢な評価を確保する。
- 問題を部分観測MDPとして定式化し、初期方針に正則化するKLペナルティ付きPPOで最適化する。
- ポリシーをトークンレベルのアクション、ターンレベルの価値関数として扱い、フィードバック情報に基づく更新を可能にする。
- 最終報酬を二値化し、無効コードへのペナルティとKL項を組み合わせて探索と忠実性のバランスを取る。
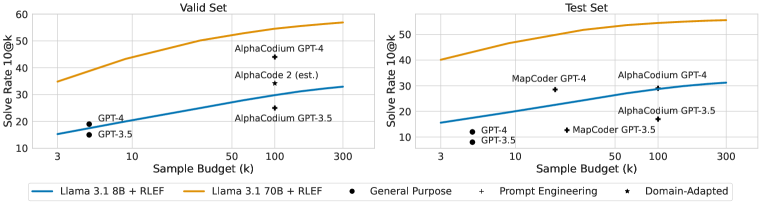
実験結果
リサーチクエスチョン
- RQ1実行フィードバックを伴う強化学習は、独立サンプリングを超えて反復的なコード合成を改善できるか。
- RQ2RLEFは複数ターンにわたりインコンテキスト実行フィードバックをLLMが効果的に活用できるようにするか。
- RQ3RLEFの改善はCodeContestsを超える他のコード生成ベンチマークへ一般化するか。
- RQ4RLEFは小規模・大規模モデルのサンプル効率とターン予算の利用にどのような影響を与えるか。
主な発見
| Model | Source | n@k | Valid Set | Test Set |
|---|---|---|---|---|
| AlphaCode 9B | Li et al. (2022) | 10@1k | 16.9 | 13.3 |
| AlphaCode 41B + clustering | Li et al. (2022) | 10@1k | 21.0 | 16.4 |
| Code Llama 34B + PPO | Xu et al. (2024) | 10@1k | 19.7 | 22.4 |
| AlphaCodium gpt-3.5-turbo-16k | Ridnik et al. (2024) | 5@100 | 25 | 17 |
| AlphaCodium gpt-4-0613 | Ridnik et al. (2024) | 5@100 | 44 | 29 |
| MapCoder gpt-3.5-turbo-1106 | Islam et al. (2024) | 1@23 | - | 12.7 |
| MapCoder gpt-4-1106-preview | Islam et al. (2024) | 1@19 | - | 28.5 |
| Llama 3.0 8B Instruct | Ours | 1@3 | 4.1 | 3.2 |
| 1ex + RLEF | Ours | 1@3 | 12.5 | 12.1 |
| Llama 3.1 8B Instruct | Ours | 1@3 | 8.9 | 10.5 |
| 1ex + RLEF | Ours | 1@3 | 17.2 | 16.0 |
| Llama 3.1 70B Instruct | Ours | 1@3 | 25.9 | 27.5 |
| 1ex + RLEF | Ours | 1@3 | 37.5 | 40.1 |
| Llama 3.1 8B Instruct | Ours | 10@100 | 21.7 | 24.8 |
| 1ex + RLEF | Ours | 10@100 | 29.8 | 28.7 |
| Llama 3.1 70B Instruct | Ours | 10@100 | 50.2 | 50.3 |
| 1ex + RLEF | Ours | 10@100 | 54.5 | 54.5 |
- RLEFで訓練されたモデルは、8Bおよび70BのLLMに対してCodeContestsで新しい最先端結果を達成し、サンプル要件を大幅に削減した。
- テストセットでは、RLEF適用後の70Bモデルがそれぞれ37.5と40.1を達成し(1@3および(1ex+RLEF 1@3))、従来手法を上回った。
- RLEFの改善はHumanEval+およびMBPP+ベンチマークへ転送され、サンプル予算を増やしても有効性が持続する。
- 推論時のフィードバックによりマルチターンの自己修正と多様だが狙いを定めた編集が可能になり、独立サンプリングへの依存を減らす。
- 真のフィードバックを用いると、乱数フィードバックより大きな利得が得られ、手法が意味のある実行信号に依存することを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。