[論文レビュー] Robust Adversarial Reinforcement Learning
RARL は、撹乱を加える敵対者の下で主人公を訓練し、ミニマックス目的を形成して、さまざまな条件でより転移しやすい頑健な方針を生成します。
Deep neural networks coupled with fast simulation and improved computation have led to recent successes in the field of reinforcement learning (RL). However, most current RL-based approaches fail to generalize since: (a) the gap between simulation and real world is so large that policy-learning approaches fail to transfer; (b) even if policy learning is done in real world, the data scarcity leads to failed generalization from training to test scenarios (e.g., due to different friction or object masses). Inspired from H-infinity control methods, we note that both modeling errors and differences in training and test scenarios can be viewed as extra forces/disturbances in the system. This paper proposes the idea of robust adversarial reinforcement learning (RARL), where we train an agent to operate in the presence of a destabilizing adversary that applies disturbance forces to the system. The jointly trained adversary is reinforced -- that is, it learns an optimal destabilization policy. We formulate the policy learning as a zero-sum, minimax objective function. Extensive experiments in multiple environments (InvertedPendulum, HalfCheetah, Swimmer, Hopper and Walker2d) conclusively demonstrate that our method (a) improves training stability; (b) is robust to differences in training/test conditions; and c) outperform the baseline even in the absence of the adversary.
研究の動機と目的
- シミュレータと現実のギャップや現実世界のRL におけるデータ不足に対処するための頑健な方針学習を動機づける。
- 訓練中に適用される不確実性を敵対的撹乱としてモデル化する。
- 頑健性を向上させるため、主人公と報酬を受ける敵対者を零和ゲームで共同訓練する。
- 複数の制御タスクに渡って安定性の改善、環境変化への頑健性、未見設定への転移を実証する。
提案手法
- 方針学習を主人公と敵対者から成る二人零和マルコフゲームとして定式化する。
- 固定された敵対者で主人公を訓練する交互最適化手順を用い、次に主人公を固定して敵対者を訓練する。
- 敵対者は事前に定められたポイントで撹乱を適用し、方針の頑健性を test する難しい軌道を誘発する。
- 敵対者の方針は破壊を最大化するよう学習され、実質的に最悪のケースの軌道をサンプリングする。
- 方針更新には神経ネットワーク近似を用いたTRPO(Trust Region Policy Optimization)を使用する。

実験結果
リサーチクエスチョン
- RQ1敵対的な撹乱モデルは、モデリング誤差やテスト時の変動に対する強化学習方針の頑健性を改善できるか。
- RQ2共同訓練された強化敵対者は、質量、摩擦、初期設定が異なる場合により良く一般化する方針を生むか。
- RQ3RARL の性能は、敵対的撹乱と変更されたテスト条件下で、TRPO などの標準的な RL ベースラインと比べてどうなるか。
主な発見
| Task | Baseline | RARL |
|---|---|---|
| InvertedPendulum | 1000±0.0 | 1000±0.0 |
| HalfCheetah | 5093±44 | 5444±97 |
| Swimmer | 358±2.4 | 354±1.5 |
| Hopper | 3614±2.16 | 3590±7.4 |
| Walker2d | 5418±87 | 5854±159 |
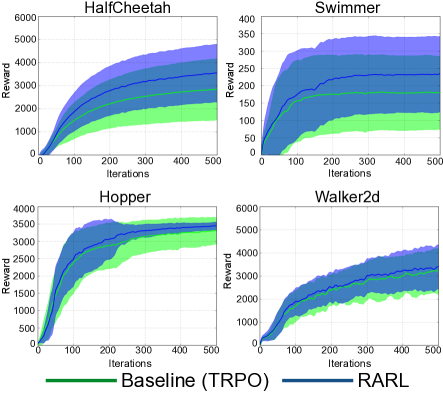
- RARL は、HalfCheetah、Swimmer、Hopper、Walker2d で、複数の初期化に対して平均報酬が高く、分散が低い。
- 敵対的撹乱下で、RARL 訓練方針はベースラインより頑健で、報酬のパーセンタイル曲線を高く維持する。
- RARL で訓練された方針は、質量と摩擦の変化に対してベースラインより一般化する。
- 可視化は、敵対者が直感的な力を適用してシステムを不安定化させ、期待される物理的課題に沿って解釈可能な方法で表れることを示す。
- 表1は、平均報酬(±SD)を報告し、RARL は多くのタスク(InvertedPendulum、HalfCheetah、Swimmer、Hopper、Walker2d)でベースラインと同等以上に一致するか上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。