[論文レビュー] Robust agents learn causal world models
本論文は、データ生成過程の近似的な因果モデルを学習することが、広範な分布シフトの下での頑健な適応に必要そして十分であることを証明し、適応ポリシーからの因果発見を可能にする方法を示す。
It has long been hypothesised that causal reasoning plays a fundamental role in robust and general intelligence. However, it is not known if agents must learn causal models in order to generalise to new domains, or if other inductive biases are sufficient. We answer this question, showing that any agent capable of satisfying a regret bound under a large set of distributional shifts must have learned an approximate causal model of the data generating process, which converges to the true causal model for optimal agents. We discuss the implications of this result for several research areas including transfer learning and causal inference.
研究の動機と目的
- 頑健な一般知性とドメイン適応における因果推論の役割を動機づける。
- 分布シフト下での後悔境界付き適応が因果モデルの学習を意味することを確立する。
- 介入下での頑健なポリシーを達成することと因果構造を学習することとの形式的同値性を提供する。
- 転移学習、因果表現学習、および因果発見への示唆について論じる。)
- method([
- 意思決定タスクを因果影響図(CIDs)および因果ベイズネットワーク(CBNs)を用いてモデル化する。
- ローカル介入およびローカル介入の混合を定義してドメインシフトをモデル化する。
- シフトしたドメイン間での最適ポリシーからの効用の祖先集合に対する因果グラフと結合分布の識別可能性を証明する(定理1)。
- 最適性を後悔境界付きポリシーへ緩和し、誤差界を伴う近似的な因果モデル識別を示す(定理2)。
- 介入下で近似的な因果モデルが後悔境界付きポリシーを可能にすることを示して十分性を実証する(定理3)。
- 転移学習、適応エージェント、および因果推論に対する解釈を論じ、ポリシー応答を用いた因果発見アプローチの概要を示す。)
提案手法
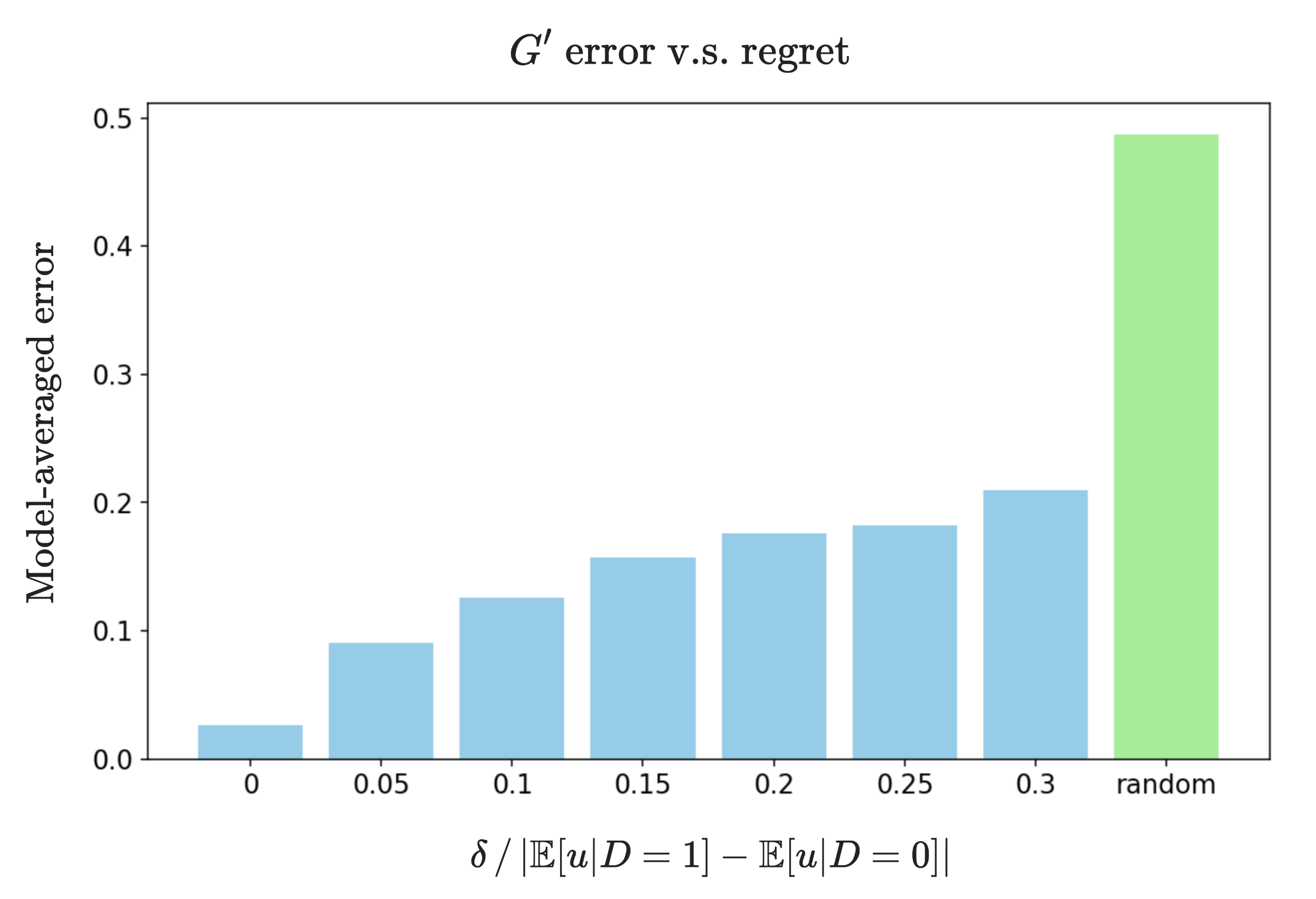
実験結果
リサーチクエスチョン
- RQ1分布シフトに対する頑健な適応は環境の因果モデルを学習することを必要とするか。
- RQ2ドメインシフト下で最適ポリシーは基礎となる因果グラフと分布を同定できるか。
- RQ3ポリシーが近似的に最適(後悔境界付き)である場合はどうなるか――近似的な因果モデルをなお回復できるか。
- RQ4さまざまな介入に対して後悔境界付きポリシーを達成するために因果世界モデルを学習することは十分か。
- RQ5これらの結果が転移学習、因果表現学習、因果発見にもたらす影響は何か。
主な発見
- 前提条件を満たすほぼすべての因果影響図に対して、局所介入の混合にわたる最適ポリシーは因果グラフと効用の祖先集合の結合分布を同定する(定理1)。
- 後悔境界付きポリシーから近似的な因果モデルを同定でき、パラメータ推定誤差は後悔レベルとともに線形に増大する(定理2)。
- 近似的な因果モデルは局所介入下での後悔境界付きポリシーを同定するのに十分である(定理3)。
- したがって、広いクラスのドメインシフトに対する頑健な適応には因果モデルの学習が必要かつ十分である。
- 結果はドメイン適応、因果表現学習、および因果発見を結びつけ、多くのドメインで訓練されたエージェントは因果世界モデルを学習し、より広範なタスク一般化を可能にすることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。