[論文レビュー] Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
本論文は、元の埋め込みを保持しつつ頑健性を向上させる、CLIPのビジョンエンコーダーに対する教師なし対向微調整法であるFAREを提案し、再学習なしで頑健な下流VLMを実現可能にする。
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
研究の動機と目的
- マルチモーダル基盤モデルにおけるビジョンエンコーダーが敵対的攻撃に脆弱である点に対処する。
- クリーンなタスク性能を保持しつつ、頑健なCLIP埋め込みを生み出す教師なし微調整スキームを開発する。
- 下流のビジョン言語モデル(VLM)へ再訓練なしで頑健性を移行させる。
- 既存の教師あり手法と教師なしのFAREを比較し、全体的な頑健性の向上を示す。
提案手法
- クリーン入力で元のCLIP埋め込みを保持する埋め込みベースの対向微調整目的を定式化する。
- FARE損失を、摂動画像の微調整後埋め込みとクリーン画像の元のCLIP埋め込みとの最大化二乗距離として定義する。
- 微調整中に敵対的摂動を生成するため、内部最大化をPGDで解く。
- 埋め込み差の最小化が、下流タスクで使用されるコサイン類似度も保持することを示す。
- 既存のVLMで言語部や統合部を再訓練せずに、元のCLIPビジョンエンコーダを頑健なFARE-CLIPに置き換える。
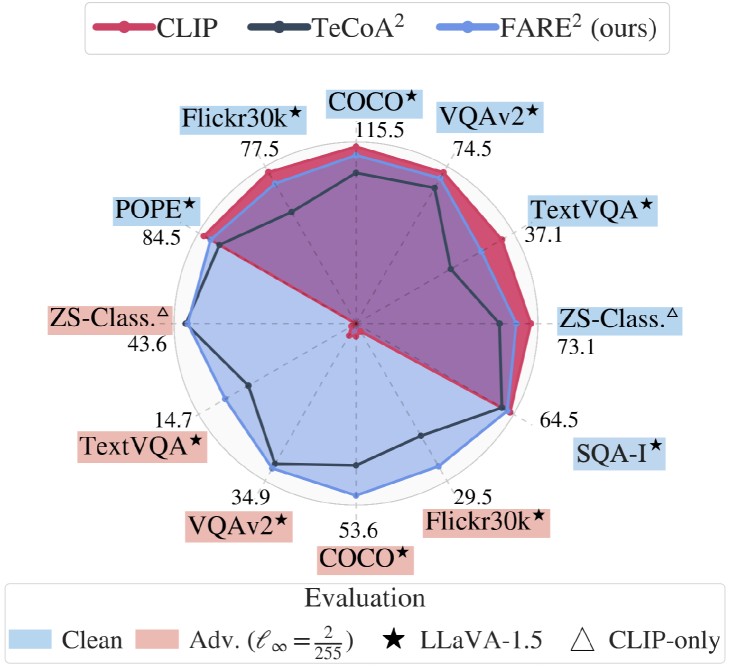
実験結果
リサーチクエスチョン
- RQ1CLIPの画像エンコーダに対する教師なし対向微調整目的が、クリーンな下流性能を劣化させることなく頑健な埋め込みを生み出せるか?
- RQ2頑健性を追加しつつ元の埋め込み挙動を保持することで、OpenFlamingoやLLaVAのような視覚言語モデルへのCLIPエンコーダのシームレスな置換を可能にするか?
- RQ3ゼロショット分類およびVLMタスクにおける清潔精度と頑健性の観点で、FAREは教師あり対向微調整(TeCoA)とどのように比較されるか?
主な発見
- FAREはクリーンデータで元のCLIP埋め込みと緊密に一致を保ち、再訓練なしにVLMへプラグアンドプレイの置換を可能にする。
- l_infinity対向摂動に対して複数の下流タスクとVLMで頑健性の向上を達成する。
- FAREはクリーンな性能を維持しつつ、いくつかのゼロショットおよびVLM評価タスクで監督付きTeCoA手法を上回る。
- VLMに頑健なCLIPエンコーダを置換すると、モデル間の敵対的画像の転送性が低下し、標的攻撃の成功率が低下する。
- FAREは、幻覚や推論ベンチマークなどの追加タスクでもTeCoAと比較して有利な結果を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。