[論文レビュー] Robust Distortion-free Watermarks for Language Models
この論文は、自己回帰言語モデルの歪みのない堅牢なウォーターマークを提案し、検出はモデル非依存であり、OPT-1.3B、LLaMA-7B、Alpaca-7Bで大幅な編集に対して強い検出力を検証します。
We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p \leq 0.01$) from $35$ tokens even after corrupting between $40$-$50\%$ of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25\%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p \leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.
研究の動機と目的
- 言語モデルによって生成されたテキストの出所情報と帰属を動機づける。
- 元のテキスト分布を保持するウォーターマークを開発する(歪みのない)。
- プロンプト知識なしで機能するモデル非依存の検出器を作成する。
- 編集や言い換えなどのテキスト撹乱に対するウォーターマーク検出の頑健性を確保する。
提案手法
- LM提供者と検出器の間で共有ウォーターマークキーを用いたウォーターマークプロトコルを定義する。
- ランダムキー列をモデル分布を保ちながらモデルサンプルへ写像する生成関数を導入する(歪みのない)。
- ウォーターマークキーに依存するかを評価するため、堅牢なシーケンス整列を用いた検出関数を定義し、p値を出力する。
- 2つのサンプリング方式を具体化する:Inverse Transform SamplingとExponential Minimum Sampling。
- 同じウォーターマークの部分列をクエリ間で再利用しないようランダム化されたラッパーshift_generateを提供し、確率的性を維持する。
- デコーダの歪みのなさを証明し、テキスト長とウォーターマークキー長に比例して拡張するp値の境界を導出する。
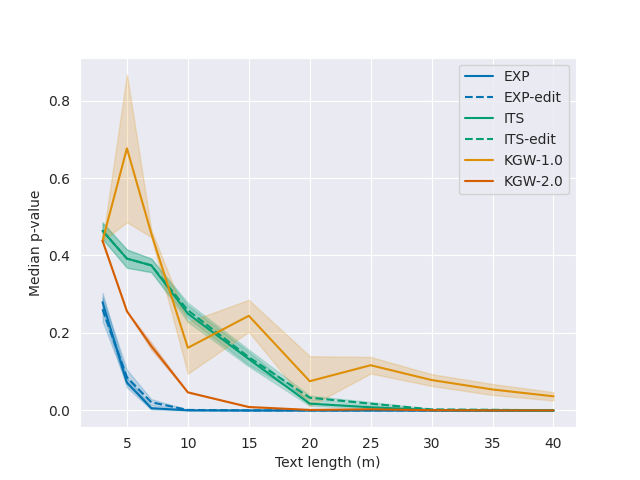
実験結果
リサーチクエスチョン
- RQ1出力分布を歪めずに言語モデルの出力にウォーターマークを埋め込むにはどうすればよいか。
- RQ2大幅なテキスト編集や言い換えの後でもウォーターマークを堅牢に検出できるか。
- RQ3ウォーターマークの潜在性とテキスト長を考慮した検出可能性(p値)の理論的限界は何か。
- RQ4異なるサンプリング戦略(Inverse TransformとExponential Minimum)は検出力と頑健性の点でどう比較されるか。
主な発見
- ウォーターマークは歪みのないもの: 生成関数はウォーターマークキー列を平均したとき、元の言語モデルと同じ分布のテキストを生み出す。
- 検出力はテキスト長と指数的に増加し、ウォーターマークキー長には線形にのみ減少する。
- Exponential minimum samplingでは、OPT-1.3BとLLaMA-7Bで40–50%のトークン置換/編集後でも35トークンからp ≤ 0.01の検出を達成する。
- Alpaca-7Bでは、約25%の応答(中央値約100トークン)がp ≤ 0.01で検出可能であり、特定の自動パラフレーズに対する頑健性はより弱い。
- パラフレージング(フランス語/ロシア語への翻訳と再翻訳)下でも大型モデルではウォーターマーク検出は可能だが、頑健性はモデルごとに異なる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。