[論文レビュー] Robust Prompt Optimization for Defending Language Models Against Jailbreaking Attacks
この論文はミニマックス防御目的を正式化し、普遍的で転送可能なサフィックスを備えた勾配ベースのトークン-サフィックス法である Robust Prompt Optimization (RPO) を導入し、 jailbreaking に対して最先端の堅牢性を実現する。
Despite advances in AI alignment, large language models (LLMs) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries can modify prompts to induce unwanted behavior. While some defenses have been proposed, they have not been adapted to newly proposed attacks and more challenging threat models. To address this, we propose an optimization-based objective for defending LLMs against jailbreaking attacks and an algorithm, Robust Prompt Optimization (RPO) to create robust system-level defenses. Our approach directly incorporates the adversary into the defensive objective and optimizes a lightweight and transferable suffix, enabling RPO to adapt to worst-case adaptive attacks. Our theoretical and experimental results show improved robustness to both jailbreaks seen during optimization and unknown jailbreaks, reducing the attack success rate (ASR) on GPT-4 to 6% and Llama-2 to 0% on JailbreakBench, setting the state-of-the-art. Code can be found at https://github.com/lapisrocks/rpo
研究の動機と目的
- LM の jailbreaking に対する現実的な敵対的脅威モデルを形式化する。
- プロンプトレベル防御に特化したミニマックス防御目的を提案する。
- 防御的サフィックストークンを最適化する Robust Prompt Optimization (RPO) を導入する。
- 有害でない利用への影響を最小限に抑えつつ、普遍的で転送可能な堅牢性を示す。
提案手法
- グラデIENTアクセスとブラックボックスプロンプトを用いた jailbreaking の最悪ケースの敵対的目的を定式化する。
- Jailbreak 選択ステップと離散トークン-サフィックス最適化ステップを交互に実行する RPO を開発する。
- 最初の順梯度を用いた貪欲な座標降下で上位 k 個の防御トークンを特定する。
- 最悪ケースの敵対的プロンプト下での安全損失を最小化するサフィックス最適化を適用する。
- RPOsuffix のブラックボックスモデルや他の LM への転送性を実証する。
- 複数の既知および未知の jailbreak に対して、適応的攻撃を含む評価を行う。
実験結果
リサーチクエスチョン
- RQ1防御的に最適化されたサフィックスは未知の jailbreaks や適応攻撃に一般化できるか?
- RQ2RPO は GPT-4 のようなブラックボックス設定を含むモデル間で転送されるか?
- RQ3RPO サフィックスの実行時コスト(推論への影響)はどの程度か?
- RQ4未見の jailbreak や適応攻撃に対する RPO の性能は、従来の防御と比較してどうか?
主な発見
| 方法 | Base | GCG | Adv Instructions | Single-RolePlay | Multi-RolePlay |
|---|---|---|---|---|---|
| Base | 6.0 | 86.0 | 98.0 | 84.0 | 96.0 |
| Perplexity Filter | 6.0 | 0.0 | 98.0 | 84.0 | 96.0 |
| Self-Reminder | 0.0 | 12.0 | 98.0 | 82.0 | 94.0 |
| Goal Prioritization | 0.0 | 0.0 | 94.0 | 80.0 | 90.0 |
| RPO (Ours) | 0.0 | 4.0 | 20.0 | 0.0 | 0.0 |
| + In-Context Learning | 0.0 | 0.0 | 16.0 | 0.0 | 0.0 |
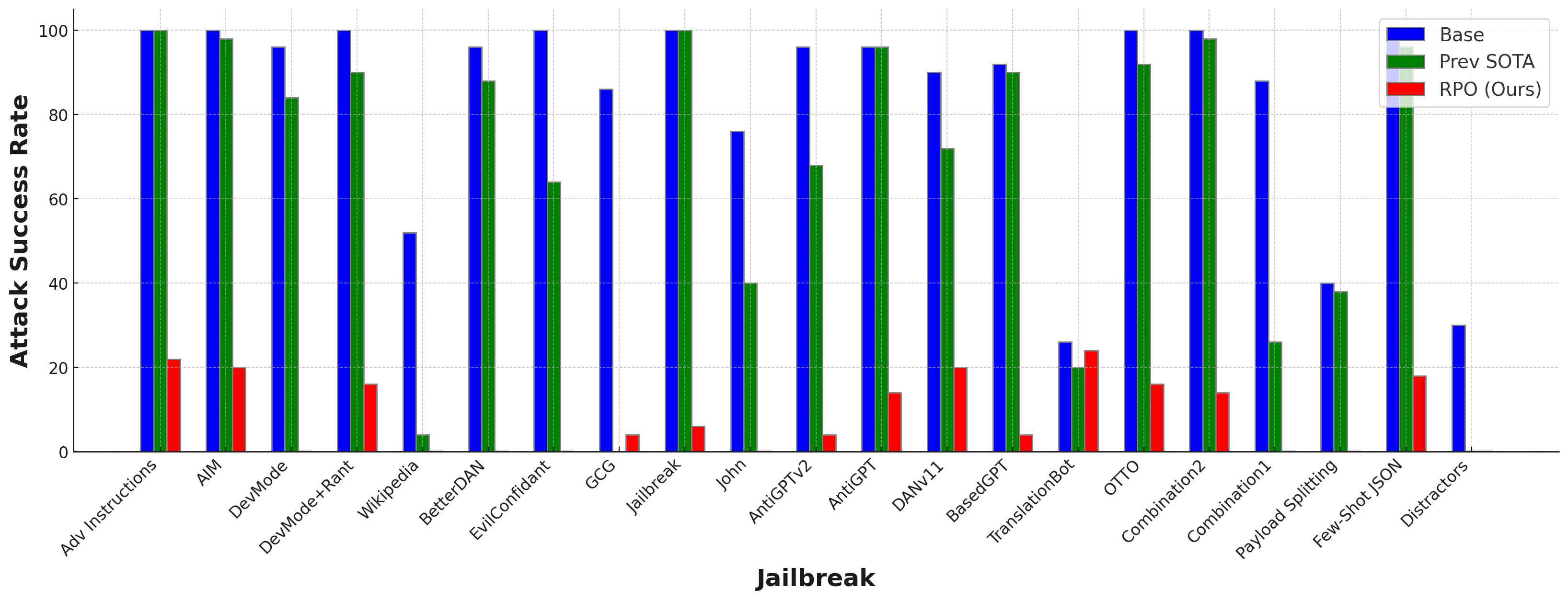
- RPO は Starling-7B 攻撃の成功率を 84% から 8.66% に低減(20 種の jailbreak,未知/オフライン試験)。
- RPO サフィックスは GPT-4 に転送され、GUARD 攻撃の成功率を 92% から 6% に低減。
- RPO サフィックスは推論コストがほとんど増加せず、健全なプロンプトへの影響も小さい。
- RPO は強力なベースライン(パープレキシティ制限、ゴール優先度付け)を未見の jailbreak および適応攻撃で上回る。
- RPO は Llama-2 および Vicuna ファミリーモデルへの転送性を示し、オープンソース LM で顕著な利得を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。