[論文レビュー] RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
RTMPose は MMPose 上に構築されたリアルタイムのトップダウン多人数姿勢推定フレームワークで、SimCCベースの座標分類、CSPNeXtバックボーン、そしてCPU/GPU/モバイルで低遅延かつ高精度を実現する展開に優しい最適化を使用します。
Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically explore key factors in pose estimation including paradigm, model architecture, training strategy, and deployment, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose's capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPose-s achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. Code and models are released at https://github.com/open-mmlab/mmpose/tree/1.x/projects/rtmpose.
研究の動機と目的
- 実時間の2D多人数姿勢推定性能(パラダイム、バックボーン、ローカリゼーション、学習、展開)に影響を与える要因を調査する。
- 産業用途の展開を前提に、速度と精度のバランスを取るリアルタイム姿勢推定フレームワークを開発する。
- 複数のバックエンドとデテクタを用いて、CPU、GPU、モバイルデバイス間の移植性を示す。
- 産業界採用を促進するオープンソースモデルと展開ガイダンスを提供する。
提案手法
- 効率的なデテクタと各人向けの軽量なポーズ推定器を組み込んだトップダウンパイプラインを採用する。
- 高い速度-精度のバランスと展開のしやすさを兼ね備えた CSPNeXt バックボーンを用いる。
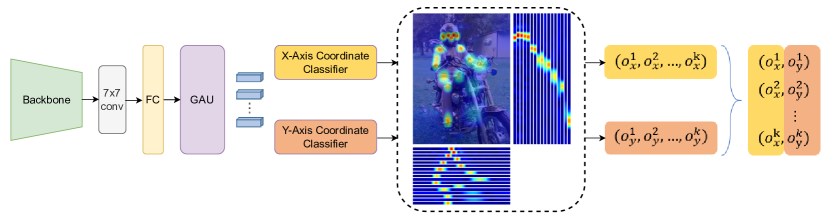
- Gaussianソフトラベルと温度スケーリングを用いた、SimCCベースの座標分類アプローチ(xとyを別々に)でキーポイントを予測する。
- キーポイント表現を改善するための自己注意リファインメント(Gated Attention Unit)を組み込む。
- UDP事前学習、EMA、フラットコサイン学習率、そして二段階の強-弱拡張を含む学習戦略を適用する。
- スキップフレーム検出、ポーズNMS(OKSベース)、OneEuro平滑化で推論パイプラインを最適化する。PyTorch、ONNX Runtime、TensorRT、ncnnで展開する。
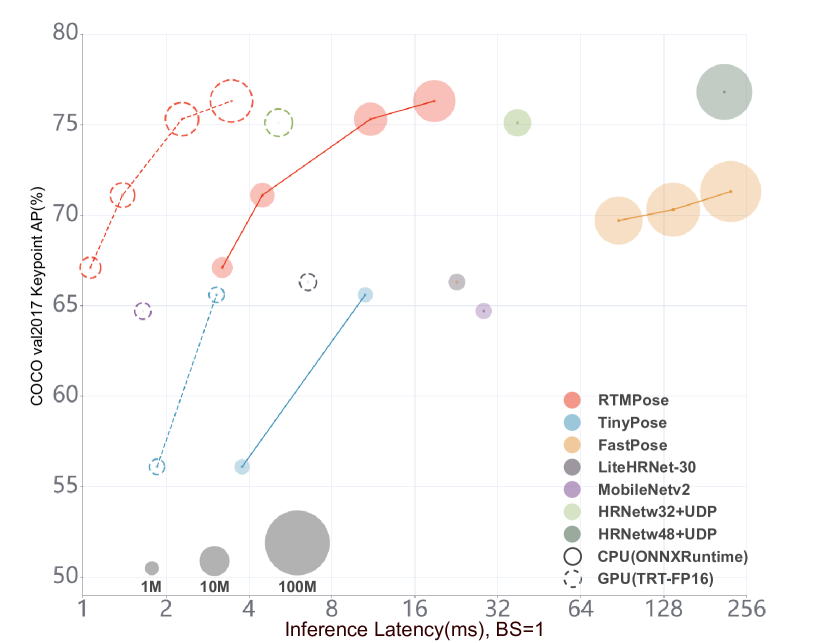
実験結果
リサーチクエスチョン
- RQ1実時間の多人数姿勢推定において、どのパラダイム、バックボーン、 Localization 方法の組み合わせが最良の速度-精度のトレードオフを生むか?
- RQ2ターゲットを絞った学習と設計選択を伴うSimCCベースの座標分類は、計算量を削減しつつ、熱図ベースのアプローチと同等以上の精度を達成できるか?
- RQ3展開最適化とプラットフォーム固有のバックエンドは、CPU、GPU、モバイル機器でのリアルタイム性能にどのように影響するか?
主な発見
| 手法 | Backbone | Detector | Det. Input Size | Pose Input Size | GFLOPs | AP | Extra Data |
|---|---|---|---|---|---|---|---|
| PaddleDetection TinyPose | Wider NLiteHRNet | YOLOv3 | 608x608 | 128x96 | 0.08 | 52.3 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | YOLOv3 | 608x608 | 256x192 | 0.33 | 60.9 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | Faster-RCNN | N/A | 128x96 | 0.08 | 56.1 | AIC(220K) |
| PaddleDetection TinyPose | Wider NLiteHRNet | Faster-RCNN | N/A | 256x192 | 0.33 | 65.6 | +Internal(unknown) |
| PaddleDetection TinyPose | Wider NLiteHRNet | PicoDet-s | 320x320 | 128x96 | 0.08 | 48.4 | |
| PaddleDetection TinyPose | Wider NLiteHRNet | PicoDet-s | 320x320 | 256x192 | 0.33 | 56.5 | |
| AlphaPose | FastPose | YoloV3 | 608x608 | 256x192 | 5.91 | 71.2 | - |
| MMPose | RTMPose-t | Faster-RCNN | N/A | 256x192 | 0.36 | 65.8 | - |
| MMPose | RTMPose-s | Faster-RCNN | N/A | 256x192 | 0.68 | 69.6 | - |
| MMPose | RTMPose-m | Faster-RCNN | N/A | 256x192 | 1.93 | 73.6 | - |
| MMPose | RTMPose-l | Faster-RCNN | N/A | 256x192 | 4.16 | 74.8 | - |
| MMPose | RTMPose-t | YOLOv3 | 608x608 | 256x192 | 0.36 | 66.0 | AIC(220K) |
| MMPose | RTMPose-s | YOLOv3 | 608x608 | 256x192 | 0.68 | 70.3 | |
| MMPose | RTMPose-m | YOLOv3 | 608x608 | 256x192 | 1.93 | 74.7 | |
| MMPose | RTMPose-l | YOLOv3 | 608x608 | 256x192 | 4.16 | 75.7 | |
| MMPose | RTMPose-m | RTMDet-nano | 320x320 | 256x192 | 1.93 | 73.2 | |
| MMPose | RTMPose-s | RTMDet-nano | 320x320 | 256x192 | 0.68 | 68.5 | |
| MMPose | RTMPose-m | RTMDet-nano | 320x320 | 256x192 | 1.93 | 73.2 | |
| MMPose | RTMPose-m | RTMDet-m | 640x640 | 256x192 | 1.93 | 75.7 | |
| MMPose | RTMPose-l | RTMDet-m | 640x640 | 256x192 | 4.16 | 76.6 |
- RTMPose-m は COCO val で 75.8% AP を達成し、CPU で 90+ FPS、GTX 1660 Ti GPU で 430+ FPS。
- RTMPose-l は COCO で 74.8% AP、報告された構成で 76.6 GFLOPs。中程度の計算量で高精度を示す。
- RTMPose-s は COCO で 72.2% AP、Snapdragon 865 で 70+ FPS、既存のオープンソースモバイルソリューションを上回る。
- SimCC を CSPNeXt バックボーンと GAU ベースのリファインメントと組み合わせると、ヒートマップベースの手法(CTベースやトランスフォーマー中心の基準)より計算コストが低いにも関わらず、競争力のある精度を得られる。
- 二段階トレーニング(COCOでUDP pre-training、次に強-弱拡張で微調整)と EMA は AP を数ポイント改善(アブレーションで示される)。
- スキップフレーム検出と後処理(OKSベースのNMSとOneEuroフィルター)は遅延を低減し、フレーム間での姿勢の頑健性を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。