[論文レビュー] Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
論文は FLOPs を削減してもメモリ帯域のボトルネックにより低遅延を保証できないと主張し、Partial Convolution (PConv) と FasterNet を導入する。FasterNet は、GPU・CPU・ARM デバイスで精度を損なうことなく、より高い FLOPS とより速い推論を実現する高速 CNN ファミリーである。
To design fast neural networks, many works have been focusing on reducing the number of floating-point operations (FLOPs). We observe that such reduction in FLOPs, however, does not necessarily lead to a similar level of reduction in latency. This mainly stems from inefficiently low floating-point operations per second (FLOPS). To achieve faster networks, we revisit popular operators and demonstrate that such low FLOPS is mainly due to frequent memory access of the operators, especially the depthwise convolution. We hence propose a novel partial convolution (PConv) that extracts spatial features more efficiently, by cutting down redundant computation and memory access simultaneously. Building upon our PConv, we further propose FasterNet, a new family of neural networks, which attains substantially higher running speed than others on a wide range of devices, without compromising on accuracy for various vision tasks. For example, on ImageNet-1k, our tiny FasterNet-T0 is $2.8 imes$, $3.3 imes$, and $2.4 imes$ faster than MobileViT-XXS on GPU, CPU, and ARM processors, respectively, while being $2.9\%$ more accurate. Our large FasterNet-L achieves impressive $83.5\%$ top-1 accuracy, on par with the emerging Swin-B, while having $36\%$ higher inference throughput on GPU, as well as saving $37\%$ compute time on CPU. Code is available at \url{https://github.com/JierunChen/FasterNet}.
研究の動機と目的
- FLOPs と実世界のレイテンシの不一致を、既存の高速ネットワークにおいて強調する。
- 冗長な計算とメモリアクセスを削減するための Partial Convolution (PConv) を導入する。
- PConv を基盤とする FasterNet のファミリを提案し、デバイスを跨いだ高スループットと低レイテンシを実現する。
- ImageNet-1k および COCO 物体検出/セグメンテーションなどのダウンストリームタスクでの FasterNet の競争力のある精度を示す。
提案手法
- FLOPS/FPs の性能に関して一般的な CNN 演算子を再評価し、メモリアクセスのボトルネックに焦点を当てる。
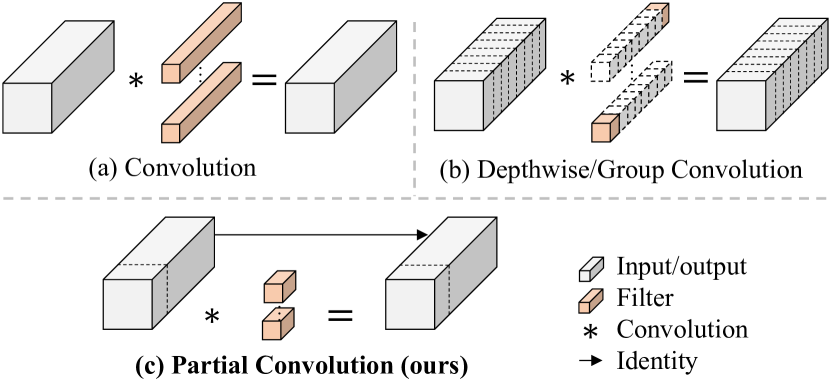
- 入力チャネルの一部のみに通常の畳み込みを適用し、他のチャネルはそのままにしておく Partial Convolution (PConv) を設計する。
- PConv を PWConv と組み合わせて T 字型の受容野を形成し、空間特徴を効率的に捉える。
- FasterNet ブロック(PConv の後に PWConv)を四段階のバックボーンに組み込み、速度と精度のための戦略的な深さ/幅の分布を取る。
- BatchNorm の融合と選択的活性化(GELU/ReLU)を用いて、デバイス間の推論レイテンシを最適化する。
実験結果
リサーチクエスチョン
- RQ1高 FLOPS(FLOPS)を活用して、共通ハードウェア上でより速い実行時間(レイテンシ/スループット)を達成できるか?
- RQ2Partial Convolution (PConv) はメモリアクセスと冗長な計算を実際に削減して、深度 wise/グループ畳込みを実際に上回ることができるか?
- RQ3PConv を基盤とした FasterNet バックボーンは、GPU/CPU/ARM デバイス全体で最先端の速度-精度のトレードオフを提供できるか?
- RQ4FasterNet モデルは、ImageNet の分類だけでなく、オブジェクト検出やインスタンス分割などのダウンストリームタスクにも有効か?
主な発見
- PConv は、入力チャネルの一部のみに畳み込みを適用することで、DWConv/GConv より高い FLOPS を達成しつつ、FLOPs を通常の Conv より削減する。
- PConv の後に PWConv を組み合わせると、通常の畳み込みを効果的に近似し、メモリアクセスを低減しつつ精度も競争力がある。
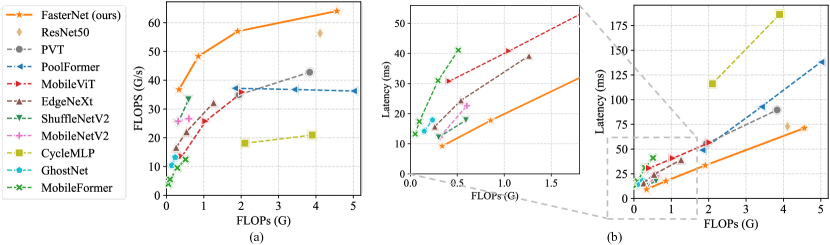
- Tiny FasterNet-T0 は、ImageNet-1k で MobileViT-XXS より GPU で 2.8 倍、CPU で 3.3 倍、ARM で 2.4 倍速く、精度は 2.9% 高い。
- Large FasterNet-L は ImageNet-1k で top-1 精度 83.5% に達し、Swin-B/ConvNeXt-B のベースラインと比較して GPU のスループットが 36%、CPU 計算時間が 37% 節約される。
- FasterNet は、CNN、ViT、MLP ベースモデルと比較して、デバイスとタスク全体(分類、検出、分割)で優れた精度-スルーガットと精度-レイテンシのトレードオフを提供する。
- COCO 物体検出/インスタンス分割では、FasterNet バックボーンは類似のレイテンシでより高い AP を生み出す。例えば FasterNet-S は ResNet50 に対してボックス AP とマスク AP を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。