[論文レビュー] Safeguarding Large Language Models: A Survey
A systematic literature review of LLM safeguarding guardrails, examining frameworks, evaluation metrics, attacks and defenses, and the path to a comprehensive, multidisciplinary guardrail design.
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as "safeguards" or "guardrails", has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
研究の動機と目的
- 提供者やオープンソースコミュニティ全体で、LLMの出力を制御するために現在使用されているガードレールのフレームワークを理解する。
- 望ましい特性の特定(例:幻覚の抑制、公平性、プライバシー、頑健性)と、それらを評価・向上させる方法。
- ガードレールに対する攻撃手法、防御、およびガードレールを強化するための強化戦略をレビューする。
- 開発ライフサイクルを含む包括的で多分野にわたるガードレール設計への道筋を議論し、課題を提案する。
提案手法
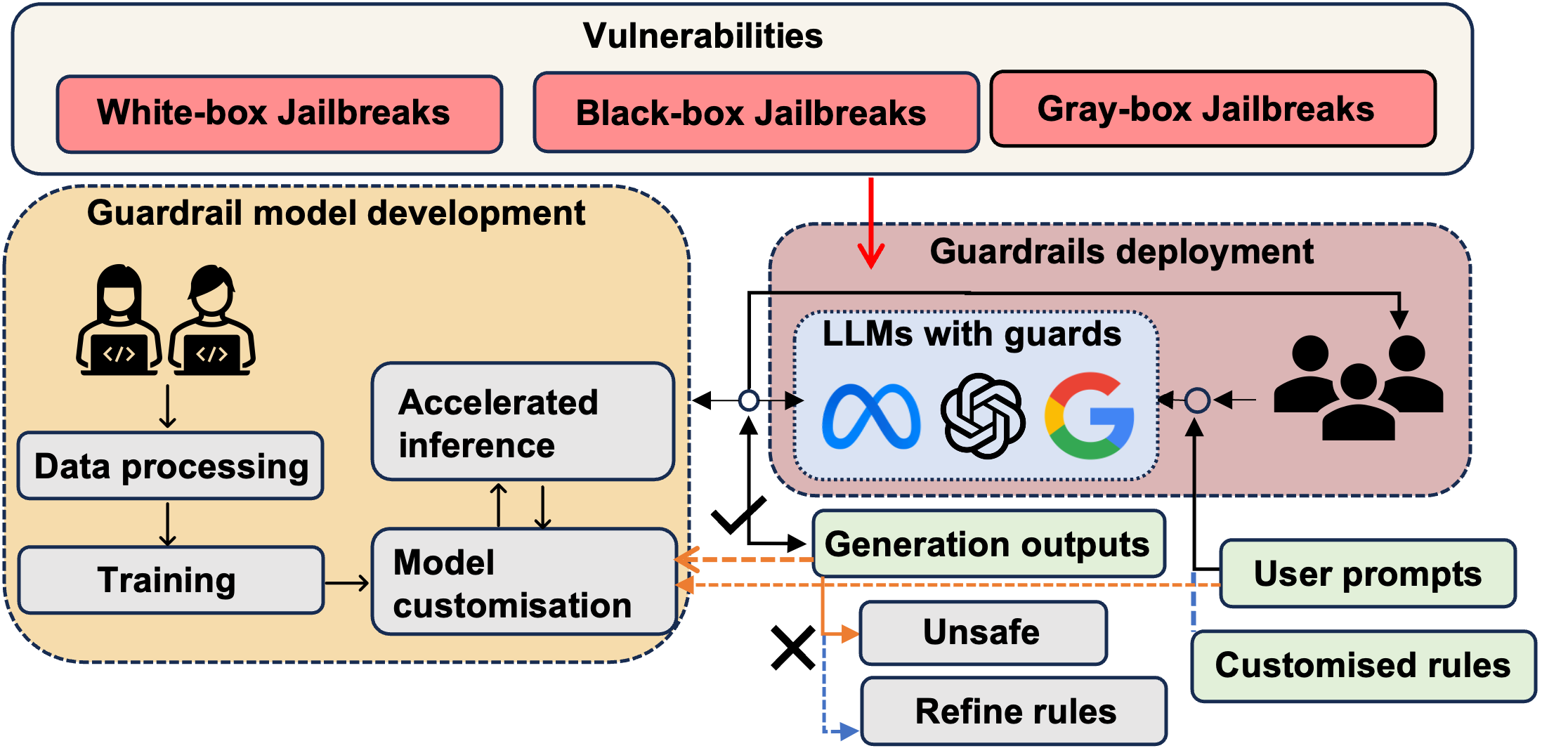
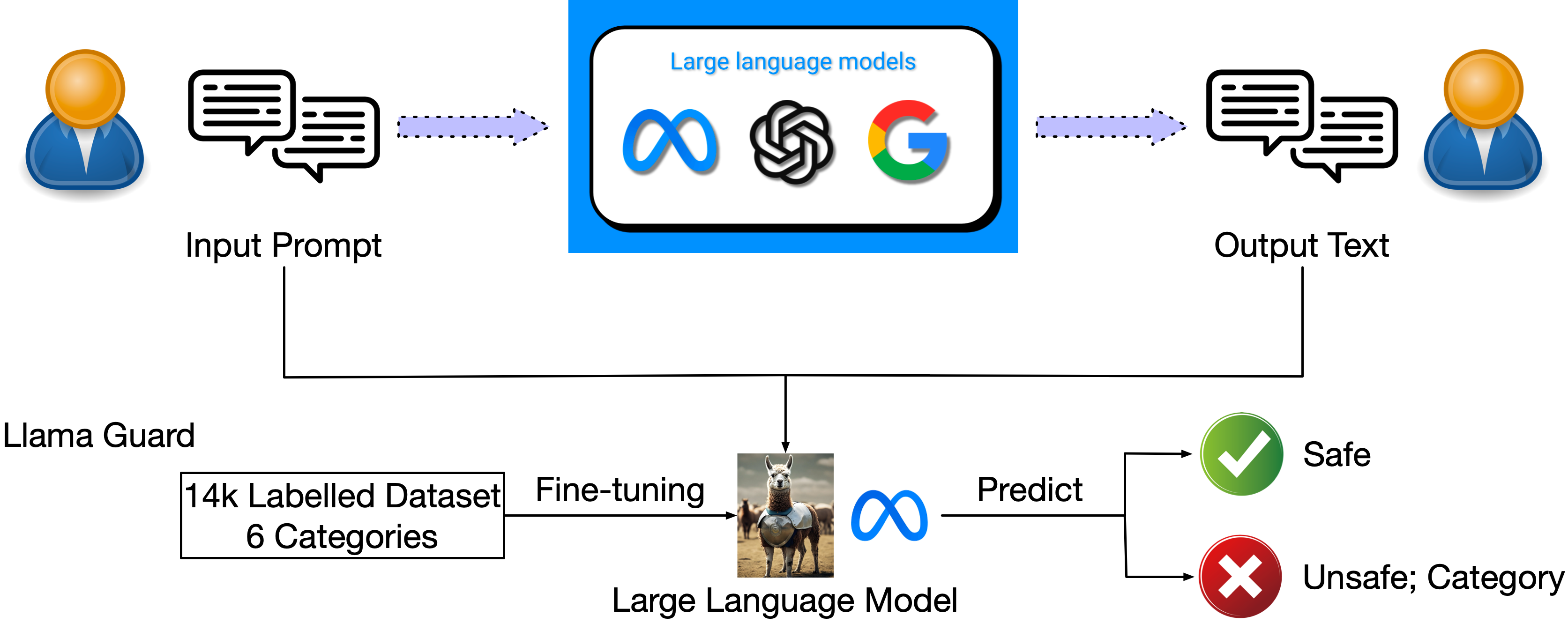
- ガードレールフレームワークとサポートソフトウェアパッケージを調査する(例:Llama Guard, Nvidia NeMo, Guardrails AI, TruLens, Guidance AI, LMQL)。
- 幻覚、公平性、プライバシー、頑健性、毒性、法的な適合性、OOD、不確実性などの特性をガードレールがどのように担保するかを分析する。
- ガードレールに関連する攻撃、防御、および強化技術を検討する。
- 安全-criticalソフトウェア標準(例:ISO-26262、DO-178B/C)およびニューラル-シンボリック統合に触発された設計上の考慮事項を議論する。
- ガードレールを実装または評価するために使用されるツールとPythonパッケージ(LangChain、AIF360、ART、Fairlearn、Detoxify)を強調する。
実験結果
リサーチクエスチョン
- RQ1生産環境とオープンソース環境で現在、LLMの出力を制御するためにどのようなガードレールのフレームワークとワークフローが展開されているか。
- RQ2ガードレールはどのような特性を強制すべきか、どのように定義・測定・向上させることができるか。
- RQ3ガードレールを迂回する攻撃は何か、これらのガードレールを守る戦略や強化する戦略は何か。
- RQ4仕様化、設計、実装、統合、検証、そして生産にわたる包括的で多分野にわたるシステムとしてガードレールをどのように設計できるか。
主な発見
- 複数のガードレールソリューションが存在する(例:Llama Guard、Nvidia NeMo、Guardrails AI)で、幻覚、毒性、法的適合性、OOD、不確実性のカバレッジが異なる。
- ガードレールは通常、いくつかのニューラル-シンボリック設計パターンのうちの一つで、緩く結合されたものからより統合的なアプローチまであり、普遍的な信頼性保証を欠く。
- 攻撃はガードレールを回避できることがあり、防御および強化戦略は継続的な評価と更新を必要とする活発な研究領域である。
- 包括的なガードレールには、多分野の方法論、ニューラル-シンボリック技術、そして安全基準に沿ったシステム開発ライフサイクルが必要である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。