[論文レビュー] Safety Cases: How to Justify the Safety of Advanced AI Systems
この論文は、AIセーフティケースを構築するためのフレームワークを提案し、4つの主張カテゴリ(能力不足、制御、信頼性、従順性)を挙げ、展開時の安全性を構造化し、評価し、潜在的に認証する方法を説明しています。
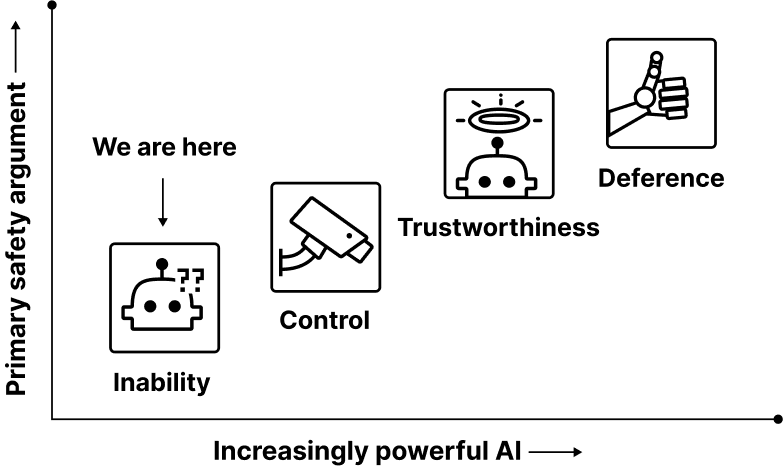
As AI systems become more advanced, companies and regulators will make difficult decisions about whether it is safe to train and deploy them. To prepare for these decisions, we investigate how developers could make a 'safety case,' which is a structured rationale that AI systems are unlikely to cause a catastrophe. We propose a framework for organizing a safety case and discuss four categories of arguments to justify safety: total inability to cause a catastrophe, sufficiently strong control measures, trustworthiness despite capability to cause harm, and -- if AI systems become much more powerful -- deference to credible AI advisors. We evaluate concrete examples of arguments in each category and outline how arguments could be combined to justify that AI systems are safe to deploy.
研究の動機と目的
- 高度なAIシステムの展開が壊滅的な事態を引き起こす可能性が低いという、構造化された合理的説明としてのセーフティケースの概念を紹介する。
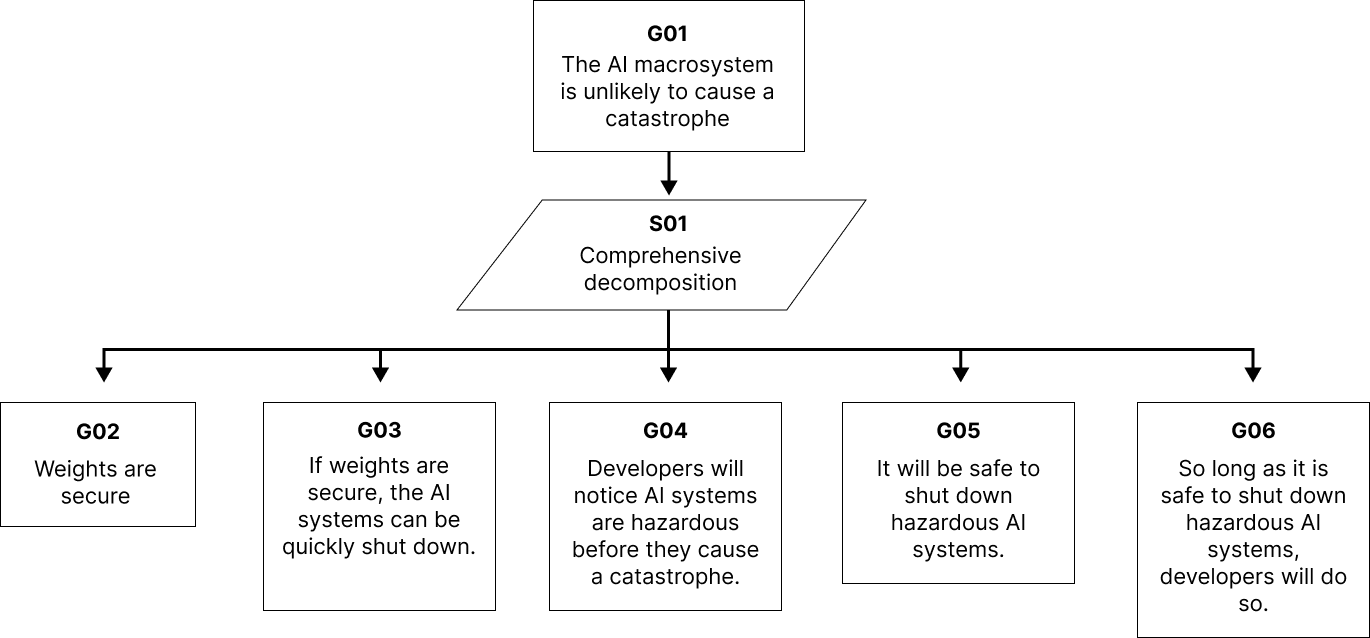
- 安全性の主張を整理し、マクロシステムとサブシステムを評価する六段階のフレームワークを提案する。
- 四つの安全性主張カテゴリ(能力不足、制御、信頼性、従順性)を識別し、具体的なテンプレートと例を提供する。
- 安全性とリスクケースの統合を論じ、機関・規制当局向けの方針提言を行う。
提案手法
- 六段階の安全-caseフレームワークの中で、AIマクロシステムと展開決定を定義する。
- 安全性主張を四つのカテゴリに分類し、その構造と適用事例を詳述する。
- 各主張タイプの具体的なテンプレートと例を提供する(危険な能力評価を含む)。
- 提案された安全性主張の実用性、最大強度、スケーラビリティを評価する。
- GSN(Goal Structuring Notation)と潜在的なリスクマトリクスを用いた総合的な安全ケースのプロセスを提案する。
- 継続的モニタリングとハード対ソフト基準を含む、機関・監査人・規制への推奨を提供する。
実験結果
リサーチクエスチョン
- RQ1高度なAIシステムを展開する際の、構造化された安全性ケースとは何か?
- RQ2安全性ケースをサブシステムに分解し、マクロレベルのリスクを評価するにはどうするのか?
- RQ3AI安全性を正当化する主要な主張カテゴリは何で、具体的にどのように実装できるのか?
- RQ4リスクケースの考慮を含め、安全性ケースを時間とともにどのように評価・更新すべきか?
主な発見
- 四つのビルディングブロックとなる安全性主張が特定される:能力不足、制御、信頼性、従順性。
- AI安全性ケースを構築・評価するための端から端までの六段階フレームワークが提案されている。
- 危険な能力評価、モニタリング、外部化された推論、テストベッドが、実用的でスケーラブルなビルディングブロックとして強調されている。
- 全体的な安全性ケースはGSN(Goal Structuring Notation)で表現でき、第三者監査人によって審査されるリスクケースで補完される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。