[論文レビュー] SAM-Med3D: Towards General-purpose Segmentation Models for Volumetric Medical Images
SAM-Med3DはSAMを完全学習可能な3Dアーキテクチャへ再設計し、大規模な体積医療データセットで訓練されることで、少数のプロンプトと高速推論で3D医用画像セグメンテーションに競争力のあるDiceスコアを達成します。
Existing volumetric medical image segmentation models are typically task-specific, excelling at specific target but struggling to generalize across anatomical structures or modalities. This limitation restricts their broader clinical use. In this paper, we introduce SAM-Med3D for general-purpose segmentation on volumetric medical images. Given only a few 3D prompt points, SAM-Med3D can accurately segment diverse anatomical structures and lesions across various modalities. To achieve this, we gather and process a large-scale 3D medical image dataset, SA-Med3D-140K, from a blend of public sources and licensed private datasets. This dataset includes 22K 3D images and 143K corresponding 3D masks. Then SAM-Med3D, a promptable segmentation model characterized by the fully learnable 3D structure, is trained on this dataset using a two-stage procedure and exhibits impressive performance on both seen and unseen segmentation targets. We comprehensively evaluate SAM-Med3D on 16 datasets covering diverse medical scenarios, including different anatomical structures, modalities, targets, and zero-shot transferability to new/unseen tasks. The evaluation shows the efficiency and efficacy of SAM-Med3D, as well as its promising application to diverse downstream tasks as a pre-trained model. Our approach demonstrates that substantial medical resources can be utilized to develop a general-purpose medical AI for various potential applications. Our dataset, code, and models are available at https://github.com/uni-medical/SAM-Med3D.
研究の動機と目的
- slice-by-slice 法を超えた3D体積医用画像の一般目的セグメンテーションを動機付け、可能にする。
- inter-slice空間情報を捉える完全な3D版SAMを開発する。
- 訓練と評価のための大規模で多様な体積医療データセットを編成する。
- 複数のデータセット、モダリティ、およびターゲットに対して既存のSAMバリアントとSAM-Med3Dをベンチマークする。
提案手法
- 3D画像エンコーダ、3Dプロンプトエンコーダ、3Dマスクデコーダを備えた完全な3DアーキテクチャへSAMを再設計する。
- 3D畳み込みと3D位置エンコーディングを使用して体積的文脈をモデル化する。
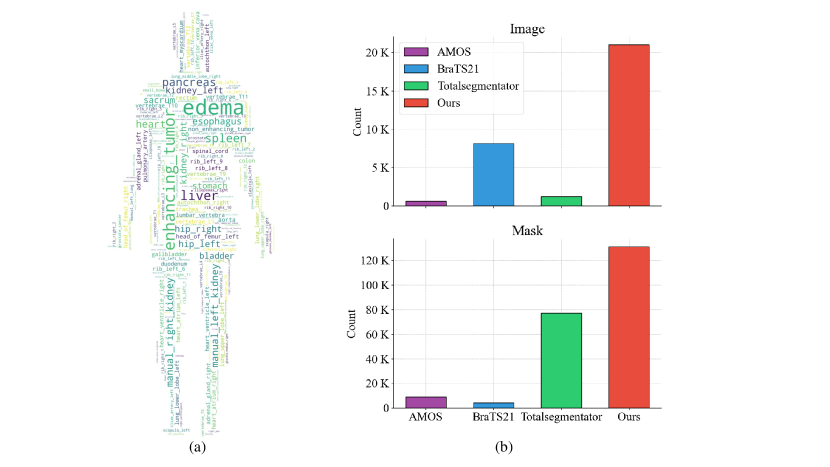
- 247カテゴリにわたる21K画像と131Kマスクからなる大規模データセットでスクラッチから訓練する。
- 単一の3Dプロンプトポイントで体積全体をターゲットにできる3Dプロンプトレジームで評価する。
- 公的データセット15件およびMICCAI 2023 ChallengeデータセットでSAMおよびSAM-Med2Dと比較する。
![Figure 1 : Illustration of SAM [ 21 ] , fine-tuned SAM (SAM-Med2D [ 6 ] ), and our SAM-Med3D on 3D Volumetric Medical Images. Both SAM and SAM-Med2D take $N$ prompt points (one for each slice) whereas SAM-Med3D uses a single prompt point for the entire 3D volume. Here, $N$ corresponds to the number](https://ar5iv.labs.arxiv.org/html/2310.15161/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1完全に学習可能な3Dアーキテクチャは、スライスごとまたは2D適応アプローチと比べて体積医用画像のプロンプトベースセグメンテーションを改善できるか。
- RQ2大規模で多様な3D医用データセットは、解剖学的構造、モダリティ、未知ターゲットへの一般化を高めるか。
- RQ3SAM-Med3Dの3Dセグメンテーションタスクにおける推論時間とプロンプト数の効率は、2D SAMバリアントと比較してどうか。
- RQ43Dエンコーダは完全監視付き3D医用セグメンテーションモデルへどの程度転移するか。
- RQ5SAM-Med3Dは複数モダリティ(CT、MRI、US)およびターゲットタイプ(臓器、骨、病変)でどの程度性能を示すか。
主な発見
- SAM-Med3Dは21Kの3D画像と131Kマスク、247カテゴリにわたるデータで学習する完全学習可能な3Dアーキテクチャを使用する。
- 1つのプロンプトポイントで評価セット全体のDiceは49.91、3、5、10プロンプトでそれぞれ56.38、58.57、60.94を達成。
- SAMの推論時間の約15%程度で、プロンプトレジーム全体にわたって優れたDiceスコアを提供。
- SAMとSAM-Med2Dに対して、解剖学的構造や病変の多くで一貫して上回り、CTおよびUSモダリティおよび未知ターゲットでプロンプトが増えると競争力ある結果を示す。
- SAM-Med3Dの事前学習済みViTエンコーダは、転移タスクの完全監視型UNETRベースラインを最大で Dice点数5.63ポイント向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。