[論文レビュー] SAM on Medical Images: A Comprehensive Study on Three Prompt Modes
本論文は医用画像に対して SAM (Segment Anything Model) を用い、3つのプロンプトモード (auto, box, point) を跨いで 12 の公開データセットで評価し、ボックスプロンプトがゼロショット性能で最も良いことを示す一方、ボックスサイズの揺らぎとプロンプトポイント数が結果に大きく影響する。
The Segment Anything Model (SAM) made an eye-catching debut recently and inspired many researchers to explore its potential and limitation in terms of zero-shot generalization capability. As the first promptable foundation model for segmentation tasks, it was trained on a large dataset with an unprecedented number of images and annotations. This large-scale dataset and its promptable nature endow the model with strong zero-shot generalization. Although the SAM has shown competitive performance on several datasets, we still want to investigate its zero-shot generalization on medical images. As we know, the acquisition of medical image annotation usually requires a lot of effort from professional practitioners. Therefore, if there exists a foundation model that can give high-quality mask prediction simply based on a few point prompts, this model will undoubtedly become the game changer for medical image analysis. To evaluate whether SAM has the potential to become the foundation model for medical image segmentation tasks, we collected more than 12 public medical image datasets that cover various organs and modalities. We also explore what kind of prompt can lead to the best zero-shot performance with different modalities. Furthermore, we find that a pattern shows that the perturbation of the box size will significantly change the prediction accuracy. Finally, Extensive experiments show that the predicted mask quality varied a lot among different datasets. And providing proper prompts, such as bounding boxes, to the SAM will significantly increase its performance.
研究の動機と目的
- 3つのプロンプトモード(auto、box、point)を用いて、医用画像セグメンテーションに対する SAM のゼロショット汎用性を評価する。
- 多様な医用イメージングモダリティ全体で最も良い性能を発揮するプロンプトモードを特定する。
- プロンプト設計(ボックスサイズ、ジッター、ポイント数)がセグメンテーション精度に与える影響を分析する。
- 将来の医療系ファンデーションモデル開発を指針とするため、異なるデータセットとモダリティにおける SAM の性能変動を検討する。
提案手法
- CT、X 線、MRI、内視鏡、超音波、OCT にまたがる 12 の公開医用画像データセットを収集する。
- 3つのプロンプトモード(auto-prompt、box-prompt、point-prompt)で SAM を評価する。
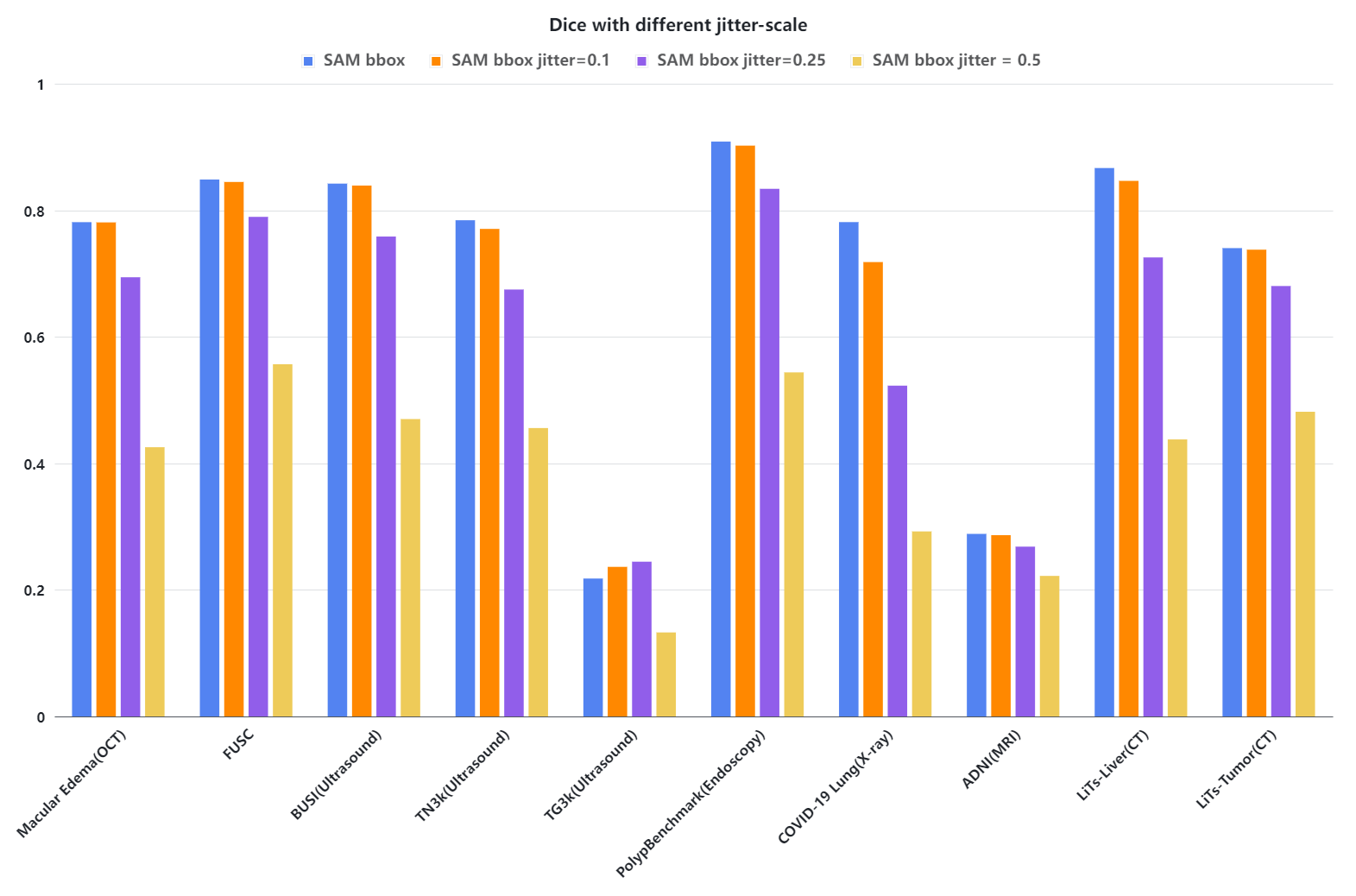
- box-prompt では、真値ベースの境界ボックスを、さまざまなジッター尺度で入力して頑健性を検討する。
- point プロンプトでは、単一、3ポイント、10ポイントのプロンプトをテストし、プロンプト密度がゼロショット性能に与える影響を観察する。
- 同じデータセット上の最新の教師あり法と SAM のゼロショット結果を比較する。
- ジッターとプロンプト設定が Dice スコアとセグメンテーション品質に与える影響を分析する。
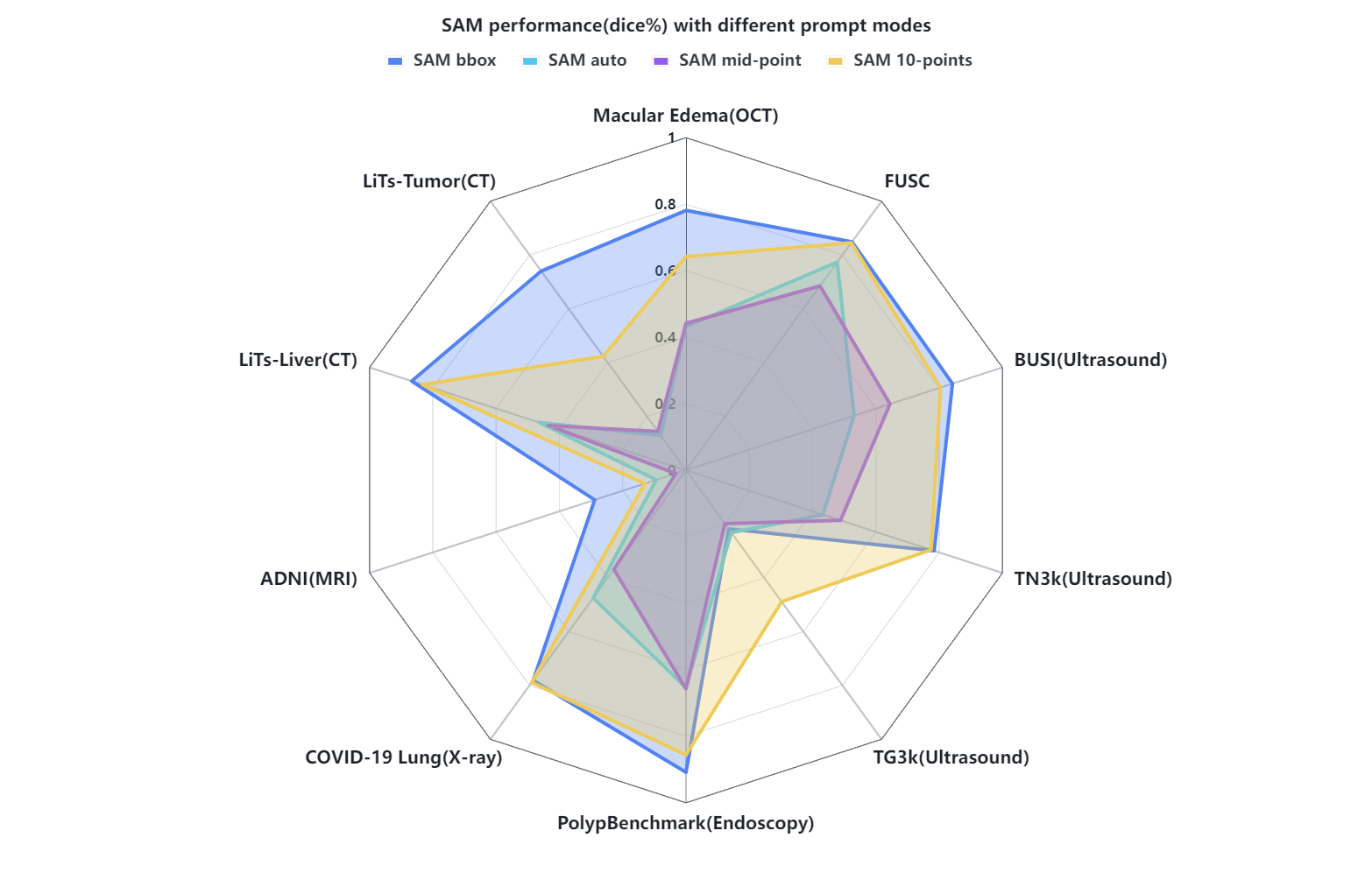
実験結果
リサーチクエスチョン
- RQ1多様な医用画像データセット全体で最高のゼロショット Dice スコアをもたらす SAM プロンプトモードはどれか?
- RQ2プロンプト設計の選択(ボックスジッター、ポイント数)は医用画像における SAM のセグメンテーション精度にどう影響しますか?
- RQ3モダリティとデータセット全体での SAM のゼロショット性能のばらつきは、教師あり法と比較してどの程度か?
主な発見
- ゼロジッターのボックスプロンプトモードは、評価対象の医用データセット全体で平均 Dice を最も良く提供する。
- ボックスプロンプトのジッターを増加させるとセグメンテーション精度が低下し、ボックスサイズと局所化への敏感さを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。