[論文レビュー] Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
本論文は入力長がLLMの推論に与える影響を分析し、長さを変数として孤立させるためにFLenQAを導入し、複数のモデルにわたり長い入力で推論性能が劣化することを示す。
This paper explores the impact of extending input lengths on the capabilities of Large Language Models (LLMs). Despite LLMs advancements in recent times, their performance consistency across different input lengths is not well understood. We investigate this aspect by introducing a novel QA reasoning framework, specifically designed to assess the impact of input length. We isolate the effect of input length using multiple versions of the same sample, each being extended with padding of different lengths, types and locations. Our findings show a notable degradation in LLMs' reasoning performance at much shorter input lengths than their technical maximum. We show that the degradation trend appears in every version of our dataset, although at different intensities. Additionally, our study reveals that the traditional metric of next word prediction correlates negatively with performance of LLMs' on our reasoning dataset. We analyse our results and identify failure modes that can serve as useful guides for future research, potentially informing strategies to address the limitations observed in LLMs.
研究の動機と目的
- より長い入力プロンプトがLLMの推論を劣化させるかを、基礎タスクを一定に保ったまま調査する。
- 入力長を因果要因として分離するため、異なる長さのパディングテキストにタスク情報を埋め込む。
- 伝統的なパープレキシティ/次語予測が長い入力の推論性能と相関するかを評価する。
提案手法
- FLenQAを導入する。これは3つの推論タスクとタスクあたり100のベースインスタンスを持つ柔軟な長さ質問応答データセット。
- 関連文脈を異なる出典と分散のパディングテキストに埋め込み、長さの異なる複数のバリエーション(250、500、1000、2000、3000トークン)を作成する。
- タスク変数を制御し、真偽問題に答えるには必要な情報の両方の要素を共に推論する必要があるようにする。
- 性能に対する位置効果を調べるため、キーパー Paragraphの位置(先頭、中間、末尾、ランダム)を変化させる。
- 一定のプロンプトと設定の下で5つのLLM(GPT-4、GPT-3.5、Gemini-Pro、Mistral 70B、Mixtral 8x7B)を評価する。
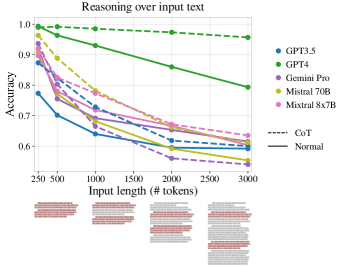
実験結果
リサーチクエスチョン
- RQ1入力長は異なるモデル全体でLLM推論性能にどのような影響を与えるか。
- RQ2入力の必須情報の配置が、長さが増すと推論の正確さに影響を与えるか。
- RQ3パディングタイプ(重複、類似、異なる)が長い入力の推論に異なる影響を及ぼすか。
- RQ4次語予測のパープレキシティは長い入力の推論性能と相関するか。
- RQ5Chain-of-Thoughtプロンプティングはモデル間で長い入力による劣化を緩和できるか。
主な発見
- 長さが長い入力になるにつれて、テスト対象のすべてのモデルで推論性能が劣化する。最大文脈サイズに達する前でも顕在する。
- 劣化はパディングがキーパーParagraphに関連しているか隣接しているか非隣接かに関係なく生じるが、強度はモデルと設定で異なる。
- 異なる無関係なパディング(Books Corpus)は、タスク内容と同様のパディングより一般的に劣化を大きく引き起こす。
- 次語予測の正確さは長い入力の推論性能と負の相関を示し(ρ = -0.95, p = 0.01)、下流タスク評価の代替にはなり得ない。
- Chain-of-Thoughtプロンプティングは多くの場合正確さを向上させるが、長い入力による劣化を完全には緩和できない;テスト対象の中でGPT-4が最も強い緩和を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。