[論文レビュー] Sample Efficient Text Summarization Using a Single Pre-Trained Transformer
本論文は、要約のために事前学習済みのデコーダー中心の Transformer LM をファインチューニングし、それを言語モデリングタスクとして扱うことで、サンプル効率を高め、エンコーダ-デコーダのベースラインよりパラメータ数が少ない状態でも競争力のある結果を得られることを示している。
Language model (LM) pre-training has resulted in impressive performance and sample efficiency on a variety of language understanding tasks. However, it remains unclear how to best use pre-trained LMs for generation tasks such as abstractive summarization, particularly to enhance sample efficiency. In these sequence-to-sequence settings, prior work has experimented with loading pre-trained weights into the encoder and/or decoder networks, but used non-pre-trained encoder-decoder attention weights. We instead use a pre-trained decoder-only network, where the same Transformer LM both encodes the source and generates the summary. This ensures that all parameters in the network, including those governing attention over source states, have been pre-trained before the fine-tuning step. Experiments on the CNN/Daily Mail dataset show that our pre-trained Transformer LM substantially improves over pre-trained Transformer encoder-decoder networks in limited-data settings. For instance, it achieves 13.1 ROUGE-2 using only 1% of the training data (~3000 examples), while pre-trained encoder-decoder models score 2.3 ROUGE-2.
研究の動機と目的
- 改善されたサンプル効率性を伴う抽象的要約のために、事前学習済み言語モデルをどのように利用できるかを示す。
- デコーダーのみの Transformer LM が、ソースを符号化し、要約を事前学習済みの重みによってのみ生成できるかを検討する。
- さまざまな事前学習構成を持つエンコーダ-デコーダアーキテクチャと比較する。
- 事前学習がサンプル効率と抽象的品質に及ぼす影響を評価する。
提案手法
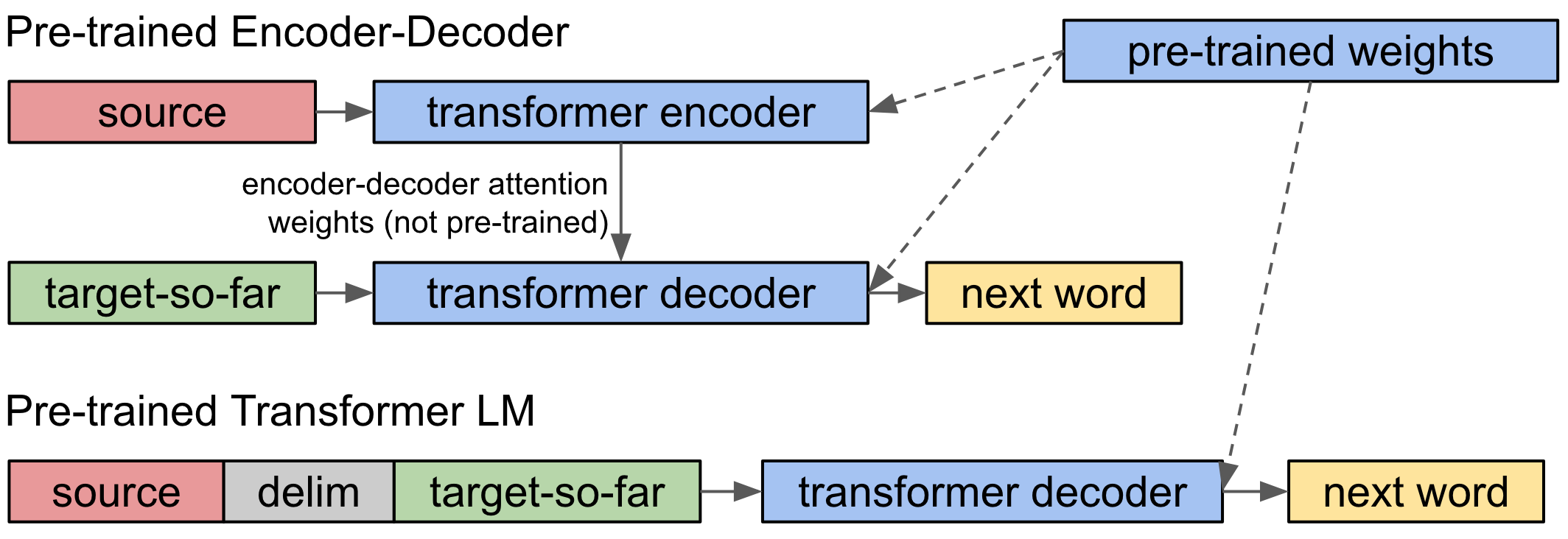
- 大規模コーパス(WikiLM)上で一方向設定の Transformer 言語モデルを事前学習する。
- 記事とその要約を1つのシーケンスとして付加して、要約を行うようデコーダーのみの Transformer LM を微調整する。
- エンコーダ、デコーダ、または両方に事前学習を適用したエンコーダ-デコーダのベースラインと比較する(エンコーダ-デコーダのアテンションは事前学習させない)。
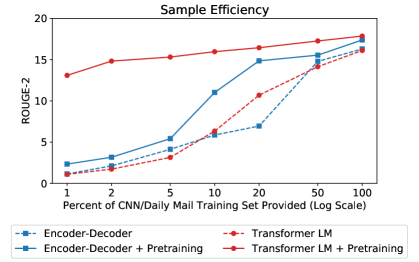
- CNN/Daily Mail データセット上で ROUGE 指標を用いて評価する。サンプル効率は、データ量を減らしてトレーニングした割合(1%、2%、5%、10%、20%、50%)で報告する。
- 推論時にはビームサイズ2のビーム探索を用いる。
実験結果
リサーチクエスチョン
- RQ1非事前学習のエンコーダ-デコーダアテンション重みを用いずに、事前学習済みデコーダーのみの Transformer LM が競争力のある抽象要約を達成できるか。
- RQ2すべてのパラメータを事前学習する(エンコーダ/デコーダ部分だけでなく)ことが、少データ環境でより優れたサンプル効率性につながるか。
- RQ3ROUGE スコアと抽象性対コピー挙動の観点で、デコーダーのみ事前学習モデルは、さまざまな事前学習構成を持つエンコーダ-デコーダアーキテクチャとどのように比較されるか。
主な発見
| Model | R1 | R2 | RL |
|---|---|---|---|
| Celikyilmaz et al. (2018) | 41.69 | 19.47 | 37.92 |
| CopyTransformer (4-layer) | 39.25 | 17.54 | 36.45 |
| GPT-2 (48-layer, zero-shot) | 29.34 | 0 8.27 | 26.58 |
| BidirEncoder-Decoder (4-layer) | 37.74 | 16.27 | 34.76 |
| Encoder-Decoder (12-layer) | 36.72 | 15.22 | 33.84 |
| Transformer LM (12-layer) | 37.72 | 16.14 | 34.62 |
- 事前学習はフルデータでROUGEスコアを約2ポイント改善する。
- デコーダーのみの事前学習は、エンコーダーのみ、またはエンコーダ-デコーダの事前学習設定より優れている。デコーダーのみの事前学習は、フルエンコーダ-デコーダモデルと競合する。
- トレーニングデータがわずか1%の場合、デコーダーのみの事前学習済み Transformer LM は ROUGE-2=13.1 を達成する一方、事前学習済みエンコーダ-デコーダモデルは 2.3 を得る。
- 本モデルは、いくつかのベースラインより高い抽象品質とソース監督に近いコピー挙動を示すが、極めて少データの設定では幻覚を生じることがある。
- 完全に事前学習されたモデル(全パラメータ)は、部分的な事前学習と比較して、データが限られた状況で大きな利得をもたらす。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。