[論文レビュー] SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
SatCLIPはSentinel-2画像に対する対比事前学習により、緯度経度埋め込みを生成して多様な地理空間予測を改善し、 unseen regions に対して一般化する глобальногоな汎用位置エンコーダを訓練します。
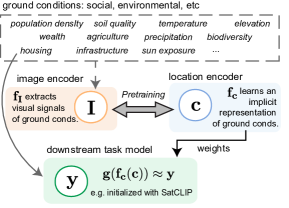
Geographic information is essential for modeling tasks in fields ranging from ecology to epidemiology. However, extracting relevant location characteristics for a given task can be challenging, often requiring expensive data fusion or distillation from massive global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP). This global, general-purpose geographic location encoder learns an implicit representation of locations by matching CNN and ViT inferred visual patterns of openly available satellite imagery with their geographic coordinates. The resulting SatCLIP location encoder efficiently summarizes the characteristics of any given location for convenient use in downstream tasks. In our experiments, we use SatCLIP embeddings to improve prediction performance on nine diverse location-dependent tasks including temperature prediction, animal recognition, and population density estimation. Across tasks, SatCLIP consistently outperforms alternative location encoders and improves geographic generalization by encoding visual similarities of spatially distant environments. These results demonstrate the potential of vision-location models to learn meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
研究の動機と目的
- グローバルで汎用的な位置エンコーダが訓練地域を超えて一般化する必要性を動機づける。
- 緯度経度を衛星画像へマッピングするCLIP風の事前学習目的を提案する。
- Sentinel-2データからグローバルに均一な事前学習データセット(S2-100K)を作成する。
- さまざまな下流の地理空間タスクで埋め込みを示す。
- コミュニティ利用のために事前学習済みSatCLIPモデルとデータセットを公開する。
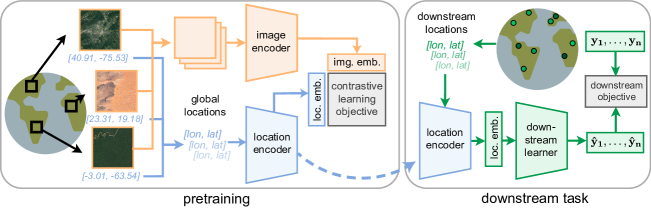
提案手法
- 緯度経度をd次元ベクトルへ写像する位置エンコーダ f_c を定義する。
- 衛星画像タイルをd次元ベクトルへ写像する画像エンコーダ f_I を定義する。
- 式1–3と同様のCLIP風の目的で、位置と対応する画像の埋め込みを整列させる事前学習を行う。
- グローバル座標エンコーディングにはSiren(SH)球面調和関数と正弦波ネットワークを用いる。
- ResNetまたはViTの画像バックボーンを採用する;訓練時には最終射影のみを除き凍結。
- S2-100Kをバッチサイズ8kで500エポック訓練する(A100 GPUs)。
実験結果
リサーチクエスチョン
- RQ1RQ1: SatCLIP埋め込みは多様な下流地理空間タスクに対してどれくらい一般化するか?
- RQ2RQ2: 未知の大陸へゼロショットまたは少数ショットの適応で地理的に一般化するか?
- RQ3RQ3: SatCLIP埋め込みは環境・社会経済的地上条件の意味ある空間的傾向を捉えるか?
主な発見
| Task | Data | SatCLIP-RN50 | SatCLIP-ViT16 | CSP (FMoW) | CSP (iNat) | GPS2Vec (tag) | GPS2Vec (visual) | MOSAIKS (Planet) |
|---|---|---|---|---|---|---|---|---|
| Air temperature | (S2-100K) | 0.27±0.03 | 0.25±0.02 | 2.81±1.11 | 4.71±1.78 | 2.37±0.00 | 2.92±0.01 | 4.61±6.05 |
| Median income | (S2-100K) | 0.71±0.16 | 0.67±0.01 | 1.39±0.07 | 1.35±0.03 | 1.06±0.00 | 1.31±0.00 | 1.31±0.07 |
| Cali. housing | (FMoW) | 2.42±0.12 | 2.62±0.28 | 5.67±0.00 | 5.68±0.01 | 1.64±0.15 | 2.20±0.14 | 4.30±0.11 |
| Elevation | (S2-100K) | 0.15±0.00 | 0.15±0.01 | 0.80±0.05 | 1.11±0.06 | 1.11±0.01 | 1.17±0.00 | 0.98±0.01 |
| Population | (S2-100K) | 0.48±0.01 | 0.50±0.02 | 1.69±0.16 | 1.72±0.28 | 1.99±0.00 | 2.28±0.00 | 1.45±0.05 |
| Countries | (Planet) | 96.00±0.14 | 95.77±0.14 | 77.78±1.66 | 82.11±1.72 | 70.35±0.06 | 67.80±0.03 | 76.16±0.50 |
| iNaturalist | (tag) | 66.03±0.54 | 65.98±0.61 | 56.73±0.83 | 60.47±0.56 | 58.78±0.48 | 53.27±0.78 | 56.73±0.80 |
| Biome | (Planet) | 94.41±0.14 | 94.27±0.15 | 75.81±1.53 | 73.18±5.58 | 69.69±0.06 | 68.29±0.11 | 79.61±0.42 |
| Ecoregions | (Planet) | 91.67±0.15 | 91.61±0.22 | 76.87±1.27 | 78.43±1.71 | 68.46±0.06 | 67.26±0.02 | 70.48±0.21 |
- SatCLIPはベースラインと比較して九つの下流タスクのうち八つで最良の予測を達成。
- SatCLIPは大陸を跨ぐ地理的一般化を強く示し、ほとんどの地域で従来のエンコーダを上回る。
- 未知の大陸へのゼロショットまたは少数ショット適応はSatCLIP埋め込みでしばしば優れている。
- 埋め込みは認識可能な環境構造をエンコードし、潜在空間に明確なバイオームクラスタリングを持つ。
- BiomesはSatCLIP埋め込みで分離可能であり、座標を超えた地上条件を捉えていることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。