[論文レビュー] SaulLM-7B: A pioneering Large Language Model for Law
SaulLM-7B は Mistral-7B を基盤とする7B規模の法域向け LLM、30B の法的トークンで訓練され、指示調整版 SaulLM-7B-Instruct を持ち、MITライセンスで公開。
In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens. SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B's performance in legal tasks. SaulLM-7B is released under the MIT License.
研究の動機と目的
- 法的テキストの理解と生成に特化した公共のオープンソース LLM を開発する。
- 大規模で多様な英語の法務コーパスを前訓練して法的言語のニュアンスを捉える。
- 法的特有のプロンプトを含む指示型ファインチューニングで性能を向上させる。
- 法域での研究と採用を促進するオープンライセンスと評価ツールを提供する。
提案手法
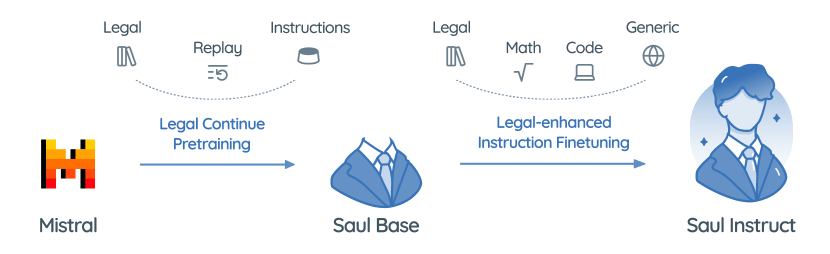
- Base model: Mistral-7B used as the foundation for SaulLM-7B.
- Continued pretraining on a curated 30B-token English legal corpus from diverse jurisdictions.
- Data cleaning and deduplication to produce high-quality legal text for pretraining.
- Instruction fine-tuning using a mix of generic and legal instruction data to create SaulLM-7B-Instruct.
- Synthetic construction of legal instruction conversations to enhance task-focused abilities.
- Evaluation protocol including LegalBench-Instruct and Legal-MMLU, with perplexity analysis on legal document types.
実験結果
リサーチクエスチョン
- RQ1Does continued pretraining on a large legal corpus improve legal task performance over generic models?
- RQ2Does adding legal instruction fine-tuning (SaulLM-7B-Instruct) yield state-of-the-art results on legal benchmarks?
- RQ3How does SaulLM-7B-Instruct compare to open-source 7B/13B models on LegalBench-Instruct and Legal-MMLU tasks?
- RQ4What is the impact of base-model choice and instruction data composition on legal reasoning and deduction tasks?
主な発見
- SaulLM-7B は standalone モデルとして強力な性能を発揮し、法的ベンチマークのいくつかの 7B ベースラインに近づくまたは一致する。
- SaulLM-7B-Instruct は LegalBench-Instruct で新しい state-of-the-art を確立し、平均スコアは 0.61、最良のオープンソース指示モデル(Mistral-7B-Instruct-v0.1)より相対的に 11% 向上。
- LegalBench-Instruct の結果は、非法的指示調整モデルを上回り、コアな法的能力(問題点の特定、規則の想起、解釈、理解)で優位。
- Legal-MMLU では、SaulLM-7B-Instruct が非法的指示調整モデルを上回る性能を3タスクで示し、最良の7Bオープンソース競合との差は3–4点。
- Perplexity analysis: SaulLM-7B-Instruct は中央値 perplexity が 8.69、Mistral-7B と比較して 5.5%、Llama2-7B(中央値 9.74)と比較して 9.20% の低減を示す。
- 法的前訓練と法的指示調整の組み合わせは大きな利益をもたらす一方で、DPO整合モデルはこの法的文脈では指示調整済みモデルに比べて劣る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。