[論文レビュー] Scalable Diffusion Models with Transformers
この論文は latent diffusion models において U-Net をトランスフォーマーのバックボーンに置き換え、Gflops ベースの DiT モデルがより良い FID スコアをもたらすこと、DiT-XL/2 が 256×256 ImageNet で最先端の FID を達成し、512×512 でも強い結果を示すことを示しています。
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
研究の動機と目的
- トランスフォーマーのバックボーンが diffusion models において U-Net を置換できるか、性能を犠牲にせずに実現できるかを評価する。
- Diffusion Transformers (DiTs) のスケーリング挙動を、フォワードパスの計算量(Gflops)を主要指標として分析する。
- モデルサイズ、パッチサイズ、条件付け機構がサンプル品質に与える影響を示す。
- LDM フレームワーク内で 256×256 および 512×512 分解能の ImageNet で DiTs を評価し、最先端ベースラインを確立する。
提案手法
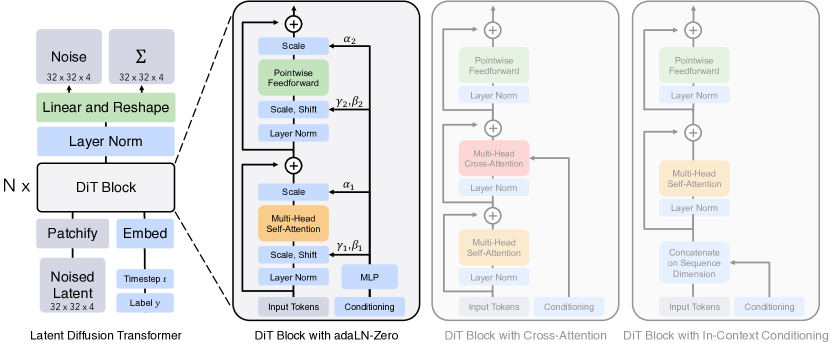
- latent diffusion models (LDMs) で U-Net をパッチを操作するトランスフォーマーへ置換する。
- ViT スタイルのトランスフォーマー・バックボーンのトークンへ latent 表現をパッチ化する操作を用いる。
- 4 つの conditioning 戦略(in-context tokens、cross-attention、adaLN、adaLN-Zero)を検討し、効率と品質の点で adaLN-Zero を採用する。
- 事前学習済みの VAE エンコーダ/デコーダを潜在空間で動作させることで、LDM フレームワーク内で ImageNet 256×256 および 512×512 で DiTs を訓練する。
- モデルの性能を主に FID-50K(250 回サンプリング步骤)で評価し、sFID、IS、Precision、Recall を補助指標として使用し、推論時には EMA 重みを用いる。
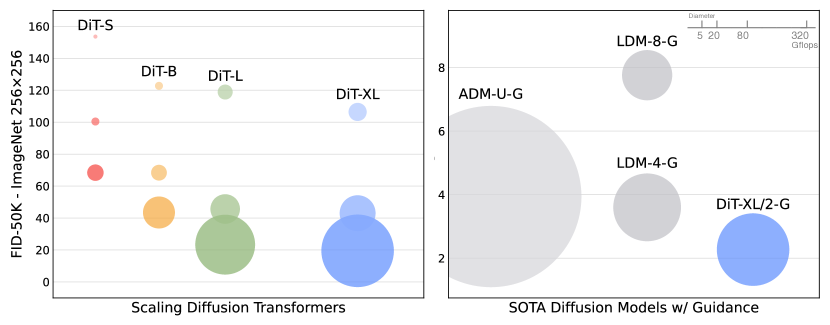
実験結果
リサーチクエスチョン
- RQ1トランスフォーマー・バックボーンは latent diffusion models における画像生成品質で U-Net ベースの diffusion models に匹敵するか、または上回るか。
- RQ2トランスフォーマーのフォワードパス計算量(Gflops)を増やすと、拡散サンプル品質はどう変化するか。
- RQ3DiTs において、計算量とサンプル品質の最も良いトレードオフを提供する conditioning メカニズムは何か。
- RQ4LDM フレームワーク下で訓練された場合、256×256 および 512×512 の ImageNet に対する DiTs の最先端性能はどの程度か。
主な発見
| Model | FID↓ | sFID↓ | IS↑ | Precision↑ | Recall↑ | Resolution | Gflops(numbers as reported) |
|---|---|---|---|---|---|---|---|
| DiT-XL/2 | 2.27 | 4.60 | 278? | 0.83 | 0.57 | 256×256 | 118.6 |
| Diag? | 3.04 | 5.02 | ... | ... | 512×512 | 524.6 | |
| ADM | 3.60? | - | - | - | - | 256×256 | 1120 |
| LDM-4 | 3.95 | - | - | - | - | 256×256 | 103.6 |
| LDM-8 | 7.76 | - | - | - | - | 256×256 | - |
- Diffusion Transformers (DiTs) は Gflops が増加するにつれてサンプル品質が向上し、深さ/幅を増やす、またはトークン数を増やすほど FID が改善する。
- DiT-XL/2 は ImageNet 256×256 で classifier-free ガイダンスを用いた最先端の FID 2.27 を達成し、従来の拡散モデルを上回る性能を示す。
- 512×512 ImageNet では DiT-XL/2 が FID 3.04 を達成し、従来の多くの拡散手法を上回りつつ、ピクセル空間の拡散モデルよりはるかに少ない Gflops で実現している。
- conditioning 戦略の中で adaLN-Zero は最小の追加 Gflops で最良の FID を提供し、in-context および cross-attention 設計を上回る。
- LDM ベースの DiTs は高い計算効率を示す:DiT-XL/2 は LDM-4/8 に対して計算効率が高く、ピクセル空間 ADM などの従来手法よりもはるかに有利。
- DiT モデルのスケーリングは、訓練段階とパッチサイズを跨いで FID の一貫した改善を示し、パラメータ数だけが品質の予測因子ではないことを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。