[論文レビュー] Scale-Aware Modulation Meet Transformer
Scale-Aware Modulation Transformer (SMT) を提案。SAM、MHMC、SAA を用いたスケール認識モジュレーションと、局所から глобальногоの依存関係を捕捉する Evolutionary Hybrid Network を組み合わせ、局所的-グローバル依存をハイブリッドに捉える。
This paper presents a new vision Transformer, Scale-Aware Modulation Transformer (SMT), that can handle various downstream tasks efficiently by combining the convolutional network and vision Transformer. The proposed Scale-Aware Modulation (SAM) in the SMT includes two primary novel designs. Firstly, we introduce the Multi-Head Mixed Convolution (MHMC) module, which can capture multi-scale features and expand the receptive field. Secondly, we propose the Scale-Aware Aggregation (SAA) module, which is lightweight but effective, enabling information fusion across different heads. By leveraging these two modules, convolutional modulation is further enhanced. Furthermore, in contrast to prior works that utilized modulations throughout all stages to build an attention-free network, we propose an Evolutionary Hybrid Network (EHN), which can effectively simulate the shift from capturing local to global dependencies as the network becomes deeper, resulting in superior performance. Extensive experiments demonstrate that SMT significantly outperforms existing state-of-the-art models across a wide range of visual tasks. Specifically, SMT with 11.5M / 2.4GFLOPs and 32M / 7.7GFLOPs can achieve 82.2% and 84.3% top-1 accuracy on ImageNet-1K, respectively. After pretrained on ImageNet-22K in 224^2 resolution, it attains 87.1% and 88.1% top-1 accuracy when finetuned with resolution 224^2 and 384^2, respectively. For object detection with Mask R-CNN, the SMT base trained with 1x and 3x schedule outperforms the Swin Transformer counterpart by 4.2 and 1.3 mAP on COCO, respectively. For semantic segmentation with UPerNet, the SMT base test at single- and multi-scale surpasses Swin by 2.0 and 1.1 mIoU respectively on the ADE20K.
研究の動機と目的
- 局所特徴モデリングと глобального コンテキストのバランスを取るハイブリッド CNN-Transformer 設計を動機づける。
- Scale-Aware Modulation (SAM) を Multi-Head Mixed Convolution (MHMC) と Scale-Aware Aggregation (SAA) と共に開発する。
- 局所からグローバル依存性の捕捉への遷移を深さに応じてシミュレートする Evolutionary Hybrid Network (EHN) を提案する。
- ImageNet, COCO, ADE20K において SMT の優位性を、パラメータと計算予算を抑えつつ示す。
提案手法
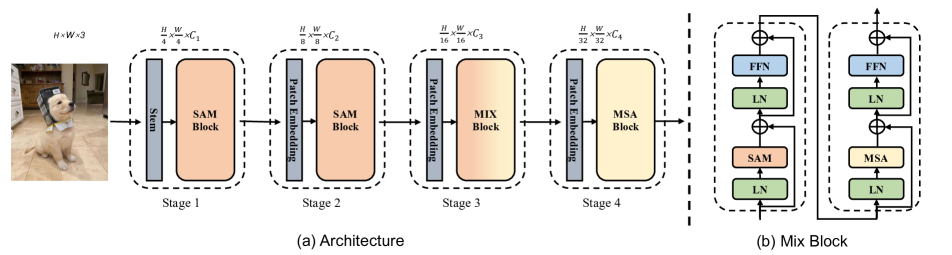
- 初期段階で従来の注意機構を置換・補完する Scale-Aware Modulation (SAM) を提案する。
- チャネルごとにヘッドを持つマルチスケール特徴を捉える Multi-Head Mixed Convolution (MHMC) を実装する。
- 軽量なヘッド間相互作用でマルチスケール特徴を統合する Scale-Aware Aggregation (SAA) を導入する。
- SAM を上位段に配置し深部段で MSA を用いる二つのハイブリッドスタッキング戦略を取り入れる、Evolutionary Hybrid Network (EHN) を採用する。
- SAM ブロックと MSA ブロックを組み合わせた Mix Block 設計を用い、局所からグローバルへの遷移をモデル化する。
- MHMC ヘッド数、アグリゲーション、スタッキングの ablazione を行い ImageNet-1K/22K、COCO、ADE20K で SMT を評価する。
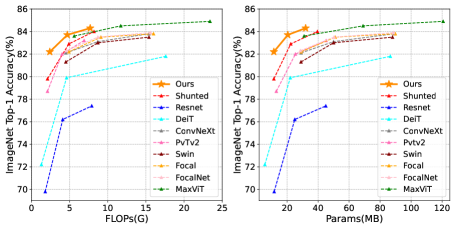
実験結果
リサーチクエスチョン
- RQ1Scale-Aware Modulation (SAM) を MHMC および SAA と組み合わせた場合、分類・検出・セグメンテーションタスクで純粋な注意機構や純粋な畳み込みブロックを上回るか。
- RQ2SAM 優位の初期段から MSA 優位の後半段へ遷移する Evolutionary Hybrid Network (EHN) は効率-精度のトレードオフを改善するか。
- RQ3MHMC ヘッド数とアグリゲーション戦略は性能とスループットにどう影響するか。
- RQ4SMT における局所-to-グローバル依存性のシフトをどのスタッキング戦略が最も適切にモデル化するか。
主な発見
| Backbone | #Params | FLOPs | ImageNet top-1 |
|---|---|---|---|
| SMT-T(Ours) | 11.5 | 2.4 | 82.2 |
| SMT-B(Ours) | 32.0 | 7.7 | 84.3 |
- SMT は ImageNet-1K で SMT-T 82.2%、SMT-B 84.3% のトップ-1 精度を達成し、類似のパラメータ数と FLOPs でいくつかの最新ベースラインを上回る。
- ImageNet-22K での事前学習と 224^2 および 384^2 での微調整は、それぞれ 87.1% および 88.1% のトップ-1 を与える。
- COCO の Mask R-CNN で SMT base は 1x の場合 Swin を 4.2 AP、3x の場合は 1.3 AP 上回る。
- ADE20K の UPerNet で SMT base は Swin に対して単一スケールで mIoU を 2.0 増加、マルチスケールで 1.1 増加。
- アブレーションにより 4MHMC ヘッドが最高の ImageNet 精度を生み、Scale-Aware Aggregation (SAA) はベースラインより 1.6% の利得を提供。
- 二つのハイブリッドスタッキング戦略を評価した結果、Sequential SAM と MSA ブロックを組み、最終段で MSA を残す戦略が最も良い性能を示した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。