[論文レビュー] Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
175時間のデータを用いたEEGからのオープンボキャブラリ音声デコードを実証し、トップ1精度48%、トップ10精度76%を達成し、約10時間と比べてデータ長依存性の強いスケーリング効果を示す。
Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48\% and a top-10 accuracy of 76\%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($\sim$10 hours), the top-1 accuracy dropped to 2.5\%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
研究の動機と目的
- データサイズがデコード精度に与える影響を評価することで、非侵襲的なEEGベースの音声転送を実用的なオープンボキャブラリBCIへ動機づける。
- EEGと音声表現をゼロショットの語句分類と再構成のために整合させる、自己教師ありCLIPベースのフレームワークを開発する。
- EMG/筋電ポテンシャルアーティファクトに対する頑健性を評価し、明示的な監督なしで音声開始検出を検討する。
提案手法
- 1人の参加者を対象に、粗読の過程で48日間にわたりEEGと音声を175時間録音した。
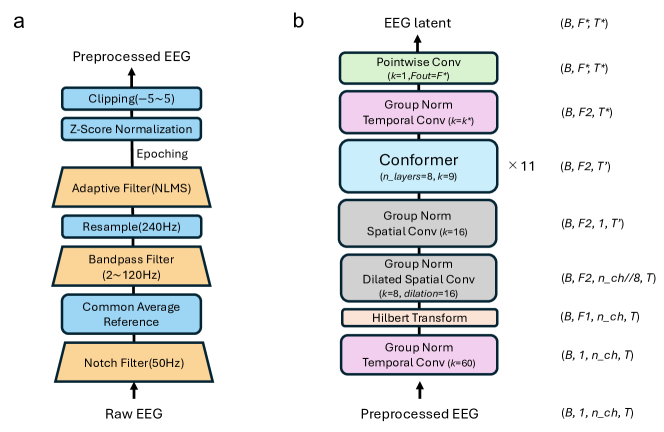
- EMGアーティファクトの緩和を含むEEG前処理を行い、データを5秒ウィンドウに分割する。
- 固定音声エンコーダ(wav2vec2.0、Whisperエンコーダ、またはEncodec)とEEGエンコーダ(HTNet + Conformer)を用いて潜在表現を生成する。
- ラベルなしでEEGと音声の潜在表現間のコサイン類似度を最大化するよう、CLIP損失を用いてEEGエンコーダを訓練する。
- EEG潜在表現から音声を再構成する拡散ボコーダーを訓練し、Mel-cepstral distortion (MCD)で評価する。
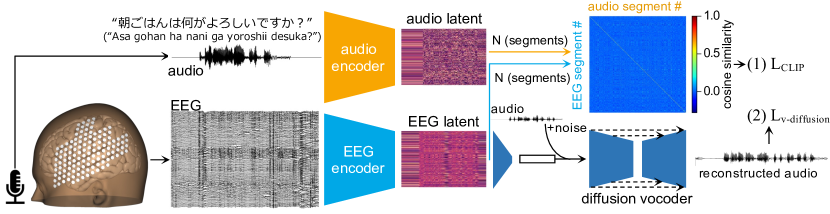
実験結果
リサーチクエスチョン
- RQ1大規模データ収集とともにEEGを用いて非侵襲的にオープンボキャブラリ音声デコードを達成できるか。
- RQ2EEGベースの音声デコードにおいて、訓練データ量はデコード精度をどのようにスケールさせるか。
- RQ3明示的な非神経的手掛かりなしに、EEG潜在ダイナミクスから音声開始/セグメント検出は可能か。
- RQ4EMGアーティファクトはEEGベースのデコードにどの程度影響するか、そしてアーティファクトを無視するよう訓練されたモデルは作れるか。
主な発見
- 全175時間で訓練した場合、512語彙のオープンボキャブラリ課題でトップ1精度48%、トップ10精度76%。
- wav2vec2.0オーディオ埋め込みを用いたゼロショット分類は、トップ1 48.5%、トップ10 76.0%を達成。
- 訓練データが増えるにつれて分類精度が改善され、データ増加下で飽和よりスケーリング傾向を示す。
- 音声再構成の平均MCDは4.68 dBで、シャッフルラベルベースラインより大幅に良好で、侵襲系ベンチマークの範囲内。
- データ量が増えるとEEG潜在表現はより明確な時間的構造を示し、単語レベルの明示的ラベルなしでデータ駆動的な音声セグメント(音声開始)検出を可能にする。
- EMGアーティファクトは、EMG混合データでEMG信号を無視するよう訓練されたモデルでは影響が限定的であり、EEGベースのデコードは主に神経活動に依存していることを示す(筋電位ではなく)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。