[論文レビュー] SceneScape: Text-Driven Consistent Scene Generation
SceneScapeは、事前学習済みのテキスト-to-画像拡散モデルと単眼深度の事前推定、およびオンライン推論時最適化を組み合わせて、テキストプロンプトとカメラ軌道から長期的で3D一貫性のある動画を生成し、統一された3Dシーンメッシュを構築します。ゼロショットで動作し、幾何学的一貫性を確保するようメッシュを逐次更新します。
We present a method for text-driven perpetual view generation -- synthesizing long-term videos of various scenes solely, given an input text prompt describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To tackle the pivotal challenge of achieving 3D consistency, i.e., synthesizing videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene. The depth maps are used to construct a unified mesh representation of the scene, which is progressively constructed along the video generation process. In contrast to previous works, which are applicable only to limited domains, our method generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles.
研究の動機と目的
- 自由形式のテキストプロンプトと与えられたカメラ軌道から、長尺な多様なシーンの動画を生成できるテキスト駆動の永続的ビュー生成を促進する。
- 大型ドメイン特化トレーニングの必要を排除するため、ゼロショット枠組みで事前学習済み画像拡散モデルと深度モデルを活用する。
- 動画生成中に統一された3Dメッシュを構築・洗練させ、3D一貫性を実現する。
- 視差、遮蔽、フレーム間の内容継続を扱えるスケーラブルなフレームワークを提供する。
提案手法
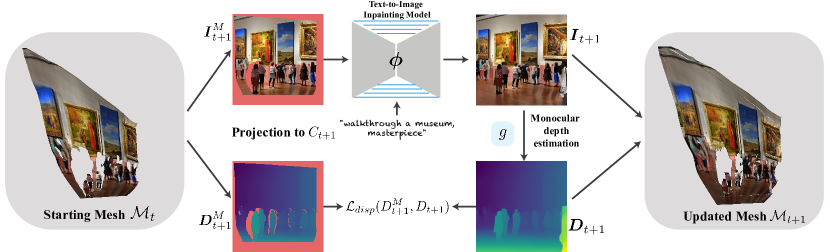
- カメラが移動する際に、新たに露出される内容を合成するために、事前学習済みのテキスト-to-画像拡散モデルを使用する。
- 単眼深度予測器で幾何を推定し、L_dispを用いた試行時微調整で深度整合性を強制する。
- シーンを表す一貫した三角形メッシュMを逐次更新し、新しい内容で展開(unprojとmerge)する。
- 知っている内容と以前の内容を保持するため、インペインティングモデルのデコーダの試行時微調整を行う(L_dec)。
- メッシュを次の視点へ投影してフレームをレンダリングし、境界・遮蔽領域をインペイントしてアーティファクトを避ける。
- レンダリング時に引き伸ばされた三角形を除去し、境界領域をインペイントして幾何学的アーティファクトを処理する。

実験結果
リサーチクエスチョン
- RQ1テキストプロンプトとカメラ軌道だけで、タスク特化のトレーニングなしに長期的で多様、かつ3D一貫性のあるウォークスルービデオを得られるか?
- RQ2単眼深度 priors と統一的なメッシュ表現をどのようにしてゼロショット設定でフレーム間の幾何学的一貫性を担保するのに使えるか?
- RQ3深度微調整とデコーダ微調整が3D一貫性と視覚品質に与える影響は?
- RQ4SceneScape は3D一貫性指標と視覚品質の点でベースラインと比較してどうか?
主な発見
| Rot. (deg.) | Trans. (%) | Reproj. (pix) | SI-RMSE | Density (%) | CLIP-AS | AMT(%) | |
|---|---|---|---|---|---|---|---|
| Ours | 0.61 | 0.01 | 0.33 | 0.17 | 0.91 | 5.85 | - |
| w/o depth f. | 2.24 | 0.02 | 0.37 | 0.41 | 0.90 | 5.75 | 52.7 |
| w/o decoder f. | 2.81 | 0.02 | 0.82 | 0.17 | 0.87 | 5.74 | 63.0 |
| w/o mesh | 3.55 | 0.04 | 0.57 | 0.18 | 0.78 | 5.73 | 69.1 |
| Warp-inpaint | 4.89 | 0.09 | 0.97 | 0.67 | 0.70 | 5.43 | 85.6 |
- SceneScapeは、多様な室内シーンにわたって高品質で幾何学的に妥当なウォークスルービデオを生成する。
- アブレーションにより、深度微調整とデコーダ微調整が深度整合性と時系列の一貫性を大幅に改善。
- メッシュを2Dワープに置き換えると3D再構成と指標が劣化し、統一メッシュの重要性が示された。
- ベースラインと比較して、3D一貫性指標とAMT研究での視覚品質でSceneScapeが上回る。
- CLIPベースのプロンプト適合性は競争力のある水準を維持しつつ、強力な3D一貫性を達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。