[論文レビュー] SeaFormer++: Squeeze-enhanced Axial Transformer for Mobile Visual Recognition
SeaFormer++ は squeeze-enhanced Axial Transformer ブロックを導入してモバイルに優しいバックボーンを構築し、ARM デバイスで低レイテンシで最先端の精度を実現します。
Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement renders these methods unsuitable on the mobile device. In this paper, we introduce a new method squeeze-enhanced Axial Transformer (SeaFormer) for mobile visual recognition. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. Coupled with a light segmentation head, we achieve the best trade-off between segmentation accuracy and latency on the ARM-based mobile devices on the ADE20K, Cityscapes, Pascal Context and COCO-Stuff datasets. Critically, we beat both the mobilefriendly rivals and Transformer-based counterparts with better performance and lower latency without bells and whistles. Furthermore, we incorporate a feature upsampling-based multi-resolution distillation technique, further reducing the inference latency of the proposed framework. Beyond semantic segmentation, we further apply the proposed SeaFormer architecture to image classification and object detection problems, demonstrating the potential of serving as a versatile mobile-friendly backbone. Our code and models are made publicly available at https://github.com/fudan-zvg/SeaFormer.
研究の動機と目的
- 限られた計算資源を持つモバイルデバイス上での高精度なピクセル単位のセグメンテーションの必要性を動機づける。
- 高解像度入力時のグローバルアテンションコストを低減する軽量な Transformer ベースのバックボーンを提案する。
- SEA attention を設計して、グローバルなセマンティック抽出と局所的なディテール強化を組み合わせる。
- SeaFormer バックボーンのファミリーと、精度-遅延のトレードオフを最適化する軽量なセグメンテーションヘッドを構築する。
- SeaFormer をセグメンテーション以外の画像分類にも適用して汎用性を示す。
提案手法
- 横方向および縦方向の squeezes を実行して複雑さを O(HW) に低減する squeeze-enhanced Axial attention (SEA attention) を導入する。
- Squeeze Axial attention を局所ディテール情報を回復するディテール強化畳み込み経路と組み合わせる。
- 位置情報を注入するために squeeze axial position embeddings を組み込む。
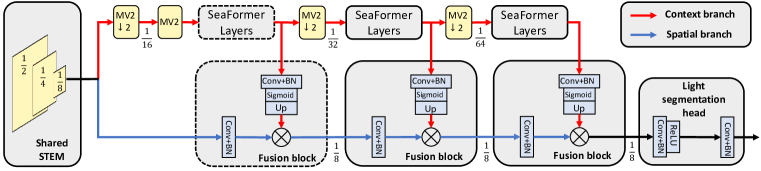
- 高解像度の空間特徴へ高レベルのセマンティクスを注入するため、コンテキストと空間の二分岐アーキテクチャと融合ブロックを使用する。
- モバイル推論を高速化する軽量なセグメンテーションヘッドを追加する。
- SeaFormer の4つのバリアント(Tiny, Small, Base, Large)を提供し、ADE20KとCityscapes、さらには ImageNet-1K 分類で結果を示す。
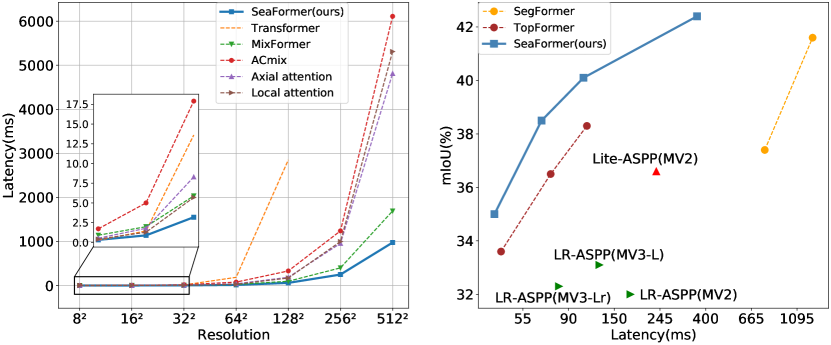
実験結果
リサーチクエスチョン
- RQ1高解像度セグメンテーションで精度を落とすことなくセルフアテンションをモバイル対応にするにはどうすればよいか?
- RQ2contextと spatial の二分岐のモバイルバックボーンは ARM デバイス上で遅延を減らしつつ競争力のある mIoU を達成できるか?
- RQ3グローバルな squeeze Axial 情報と局所ディテール強化を組み合わせると、従来のアテンションや他の効率的なバックボーンを上回るか?
- RQ4SeaFormer はバックボーンとしてセグメンテーションだけでなく画像分類でも良好に機能するほど汎用性があるか?
主な発見
| Backbone | FLOPs | mIoU(val) | mIoU(test) | Latency (ms) |
|---|---|---|---|---|
| SeaFormer-T | 0.6G | 35.0 | 35.8 ± 0.35 | 40 |
| SeaFormer-S | 1.1G | 38.1 | 39.4 ± 0.25 | 67 |
| SeaFormer-B | 1.8G | 40.2 | 41.0 ± 0.45 | 106 |
| SeaFormer-L | 6.5G | 42.7 | 43.7 ± 0.36 | 367 |
- SeaFormer の variants は mobile-friendly なライバルおよび Transformer ベースのベースラインと比較して ADE20K および Cityscapes で優れた精度-遅延のトレードオフを達成。
- SeaFormer-B および SeaFormer-L は MobileNetV3 や他の軽量バックボーンより低遅延または同等の遅延でより高い mIoU を達成(例:SeaFormer-B: 40.2 mIoU with 106 ms latency; SeaFormer-L: 42.7 mIoU with 367 ms latency)。
- SeaFormer-S* は 67 ms の遅延で 39.4 ± 0.25 mIoU、SeaFormer-L* は 367 ms の遅延で 43.7 ± 0.36 mIoU を達成し、モバイル規模の遅延で高い精度を示す。
- アブレーションにより、ディテール強化と squeeze Axial attention の組み合わせは、それぞれ単独より意味のある改善を生むことが示された。
- SeaFormer-T は軽量ヘッドと低遅延(モバイル機器上の 40 ms 領域)で競争力のある結果を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。