[論文レビュー] Searching for Best Practices in Retrieval-Augmented Generation
この論文は、取得拡張生成(RAG)パイプライン構築のベストプラクティスを体系的に調査し、クエリ分類、チャンク化、埋め込みモデル、ベクトルデータベース、取得方法、リランキング、リパッキング、要約、ジェネレータ微調整を含むコンポーネントの選択を評価し、マルチモーダル取得と効率重視の構成を強調する。
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
研究の動機と目的
- 最適なRAGワークフローのコンポーネントとその組み合わせを大規模実験を通じて特定する。
- RAGの性能を一般的なタスク・領域特化・マルチモーダルタスクで評価するための包括的な評価フレームワークとデータセットを提供する。
- マルチモーダル取得が視覚入力のQAを改善し、取得を生成として扱うアプローチを用いてマルチモーダルコンテンツ生成を高速化できることを示す。
提案手法
- 各RAGモジュールごとに代表的なタスクでの性能に基づく候補手法を三段階で選択する。
- 一つずつのアブレーションで全体のRAG性能に対する各モジュールの寄与を測定する。
- 異なるシナリオに対して性能または効率を優先する組み合わせを経験的に探求する。
- 評価は多様なタスク群(常識、事実検証、オープンドメインQ&A、マルチホップQ&A、医療Q&A)を用い、指標には忠実性、文脈関連性、回答関連性、回答正確性を含む。
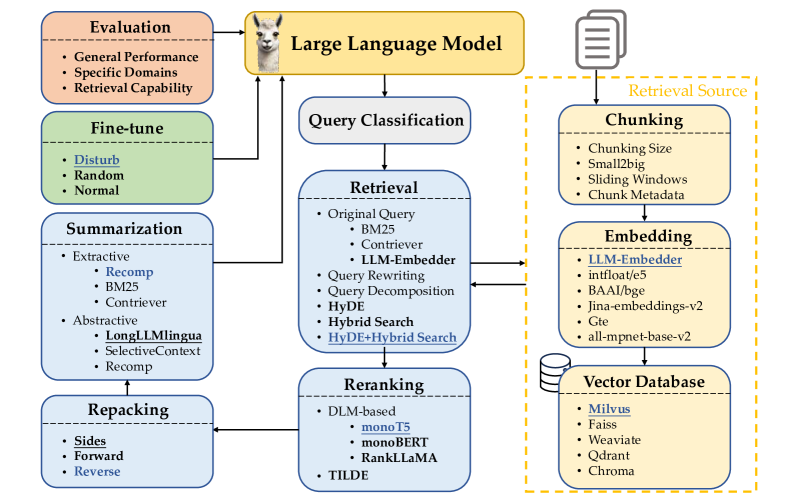
実験結果
リサーチクエスチョン
- RQ1RAGパイプライン(クエリ分類、チャンク化、埋め込み、ベクトルストア、取得、リランキング、リパッキング、要約、ジェネレータ微調整)の各モジュールで最も性能の高い手法は何か。
- RQ2各モジュールが全体のRAG性能にどのように寄与し、どの組み合わせが精度と効率の最良のトレードオフを生み出すのか。
- RQ3マルチモーダル取得は視覚入力のQAを大幅に改善し、取得を生成としての戦略を介してマルチモーダルコンテンツ生成を加速できるのか。
主な発見
| 方法 | TREC DL19 mAP | TREC DL19 nDCG@10 | TREC DL19 R@50 | TREC DL19 R@1k | 待機時間 | DL20 mAP | DL20 nDCG@10 | DL20 R@50 | DL20 R@1k | 待機時間 |
|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | 30.13 | 50.58 | 38.32 | 75.01 | 0.07 | 28.56 | 47.96 | 46.18 | 78.63 | 0.29 |
| Contriever | 23.99 | 44.54 | 37.54 | 74.59 | 3.06 | 23.98 | 42.13 | 43.81 | 75.39 | 0.98 |
| LLM-Embedder | 44.66 | 70.20 | 49.06 | 84.48 | 2.61 | 45.60 | 68.76 | 61.36 | 84.41 | 0.71 |
| + Query Rewriting | 44.56 | 67.89 | 51.45 | 85.35 | 7.80 | 45.16 | 65.62 | 59.63 | 83.45 | 2.06 |
| + Query Decomposition | 41.93 | 66.10 | 48.66 | 82.62 | 14.98 | 43.30 | 64.95 | 57.74 | 84.18 | 2.01 |
| + HyDE | 50.87 | 75.44 | 54.93 | 88.76 | 7.21 | 50.94 | 73.94 | 63.80 | 88.03 | 2.14 |
| + Hybrid Search | 47.14 | 72.50 | 51.13 | 89.08 | 3.20 | 47.72 | 69.80 | 64.32 | 88.04 | 0.77 |
| + HyDE + Hybrid Search | 52.13 | 73.34 | 55.38 | 90.42 | 11.16 | 53.13 | 72.72 | 66.14 | 90.67 | 2.95 |
- スパース検索(BM25)と密接検索をHyDEベースのクエリ/ドキュメント変換と組み合わせたハイブリッド検索は、適度な遅延で強力な性能を発揮する。
- 評価設定下では、クエリ書換えやクエリ分解はHyDEやハイブリッド戦略ほどの検索性能には寄与しなかった。
- 標準ベンチマークでの総合的な最良RAG性能は、HyDEとHybrid Searchの組み合わせで実現され、LLM-Embedder埋め込みと強力なリランカー(monoT5)を使用。
- ジェネレータ微調整時に関連ドキュメントとランダムドキュメントを適度に混ぜると、関連ドキュメントのみやランダムドキュメントのみを用いる場合よりロバスト性と有効性が向上する。
- マルチモーダル取得は視覚入力のQAを大幅に強化し、取得を生成としてのアプローチによりマルチモーダルなコンテンツ生成を高速化する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。