[論文レビュー] Secrets of RLHF in Large Language Models Part I: PPO
この論文は、PPO を用いた RLHF を用いて LLM を整合させることを分析し、安定した訓練の鍵としてポリシー制約を特定し、訓練の安定性とスケーラビリティを向上させる PPO-max を導入する。公開済みの報酬モデルと PPO コードを併せて紹介。
Large language models (LLMs) have formulated a blueprint for the advancement of artificial general intelligence. Its primary objective is to function as a human-centric (helpful, honest, and harmless) assistant. Alignment with humans assumes paramount significance, and reinforcement learning with human feedback (RLHF) emerges as the pivotal technological paradigm underpinning this pursuit. Current technical routes usually include extbf{reward models} to measure human preferences, extbf{Proximal Policy Optimization} (PPO) to optimize policy model outputs, and extbf{process supervision} to improve step-by-step reasoning capabilities. However, due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle. In the first report, we dissect the framework of RLHF, re-evaluate the inner workings of PPO, and explore how the parts comprising PPO algorithms impact policy agent training. We identify policy constraints being the key factor for the effective implementation of the PPO algorithm. Therefore, we explore the PPO-max, an advanced version of PPO algorithm, to efficiently improve the training stability of the policy model. Based on our main results, we perform a comprehensive analysis of RLHF abilities compared with SFT models and ChatGPT. The absence of open-source implementations has posed significant challenges to the investigation of LLMs alignment. Therefore, we are eager to release technical reports, reward models and PPO codes, aiming to make modest contributions to the advancement of LLMs.
研究の動機と目的
- LLM の整合性のための RLHF フレームワークとその訓練要素(SFT、RM、PPO)を説明する。
- 報酬モデルの品質と PPO の設計がポリシー学習と安定性に与える影響を評価する。
- PPO の実装の詳細を調査し、訓練の安定性と性能を左右する要因を特定する。
提案手法
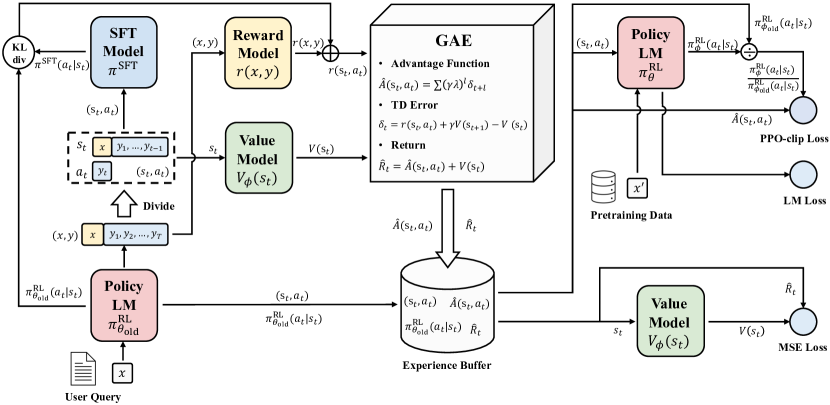
- RLHF フレームワークを分解し、PPO の内部動作を再評価して、構成要素がポリシー訓練にどのように影響するかを研究する。
- 訓練の安定性を高め、より大規模なコーパスでより長い訓練ステップを可能にする高度な PPO 変種である PPO-max を提案する。
- 中国語および英語の報酬モデルを開発・公開し、モデル間一般化能力を備える。
- アクション空間指標(困惑度、応答長、SFT への KL 発散)を用いて PPO 訓練の安定性をモニタリングする。
- 7B および 13B の SFT モデルで PPO-max を評価し、ChatGPT との整合性を比較する。
実験結果
リサーチクエスチョン
- RQ1RLHF 設定において、報酬モデルの品質は RL 方針の性能をどのように上限づけるか。
- RQ2LLM における訓練の安定性と整合性の結果に最も影響を与えるPPO設計の選択肢は何か。
- RQ3最適化された PPO 変種(PPO-max)は安定性を改善し、言語能力を損なうことなくより大きな訓練ステップを可能にできるか。
- RQ4言語とデータ(英語対中国語)は報酬モデルの訓練と RLHF の結果にどのように影響するか。
主な発見
- 報酬モデルの品質はポリシーモデルの性能の上限を直接決定します。
- PPO 内のポリシー制約は安定した RLHF 訓練にとって重要です。
- PPO-max は訓練の安定性を向上させ、より長い訓練ステップとより大きなコーパスをサポートします。
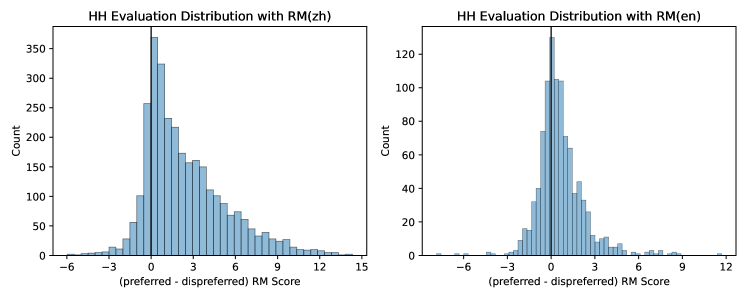
- 中国語の報酬モデルは、彼らのテストでは英語のものより人間の好みとの整合性が HH 評価で強いことを示しています。
- RLHF 学習済みモデルは時にはクエリの深い意味をよりよく捉え、ユーザーにより直接響く応答を生成することがあります。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。