[論文レビュー] Securing Large Language Models: Threats, Vulnerabilities and Responsible Practices
この論文は、大規模言語モデル(LLM)のセキュリティとプライバシーの懸念、敵対的攻撃への脆弱性、悪用リスク、緩和戦略を概観し、今後の研究方向を提案します。
Large language models (LLMs) have significantly transformed the landscape of Natural Language Processing (NLP). Their impact extends across a diverse spectrum of tasks, revolutionizing how we approach language understanding and generations. Nevertheless, alongside their remarkable utility, LLMs introduce critical security and risk considerations. These challenges warrant careful examination to ensure responsible deployment and safeguard against potential vulnerabilities. This research paper thoroughly investigates security and privacy concerns related to LLMs from five thematic perspectives: security and privacy concerns, vulnerabilities against adversarial attacks, potential harms caused by misuses of LLMs, mitigation strategies to address these challenges while identifying limitations of current strategies. Lastly, the paper recommends promising avenues for future research to enhance the security and risk management of LLMs.
研究の動機と目的
- モデルベース、トレーニング時、推論時の各段階での使用から生じるセキュリティとプライバシーの懸念を特定する。
- 敵対的攻撃と悪用による脆弱性と潜在的な害を分類する。
- レッド/グリーン・チーミング、モデル編集、ウォーターマーキング、検出手法などの緩和戦略をレビュー・評価する。
- LLMのセキュリティとリスク管理を改善する将来の研究方向を提案する。
提案手法
- モデルベース、トレーニング時、推論時のカテゴリに分けた脆弱性と対策を分類する。
- memorization、データ漏洩、プライバシーリスクに関する既存文献をレビューする。
- コード生成のセキュリティ懸念と検出・ウォーターマーキング手法の有効性を分析する。
- レッドチーミング、グリーン・チーミング、ウォーターマーキング、検出技術を含む緩和戦略を要約し、それらのトレードオフを論じる。
- LLMのセキュリティにおけるギャップを特定し、将来の研究の方向性を提案する。
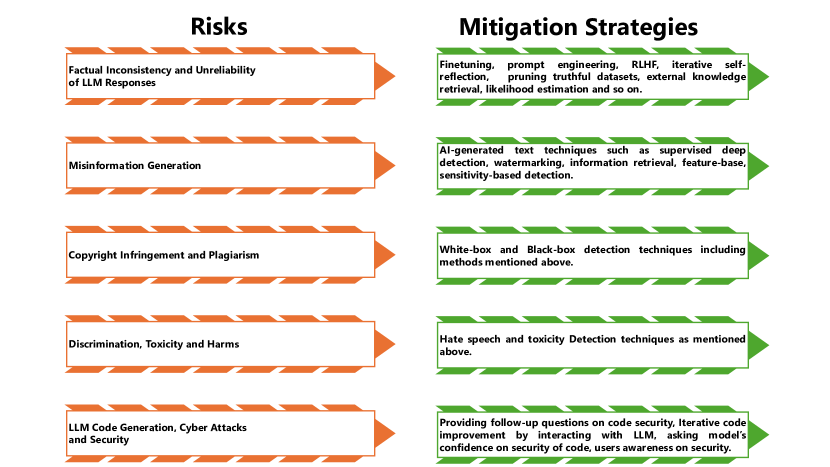
実験結果
リサーチクエスチョン
- RQ1LLMs に関連する主なセキュリティとプライバシーの懸念は何か?
- RQ2敵対的攻撃はモデルベース、トレーニング時、推論時の脆弱性をどのように悪用するのか?
- RQ3LLMs から生じうる悪用と害は何で、それをどう緩和できるのか?
- RQ4現在の緩和戦略にはどんな限界があり、将来の研究はどこに焦点を当てるべきか?
主な発見
- LLMs は大規模ウェブコーパスで事前学習することによる情報漏えいと memorization のリスクを抱える。
- LLM が生成するコードには悪用可能なセキュリティホールが存在する。
- 脆弱性はモデルベース、トレーニング時、推論時のカテゴリにまたがり、各々に対する対策が存在する。
- 緩和戦略にはレッドチーミング、モデル編集、ウォーターマーキング、検出手法が含まれ、それぞれに制約とトレードオフがある。
- 本論文は、LLM のセキュリティとリスク管理を向上させるための将来の研究方向を提示する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。