[論文レビュー] See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge-based Visual Reasoning
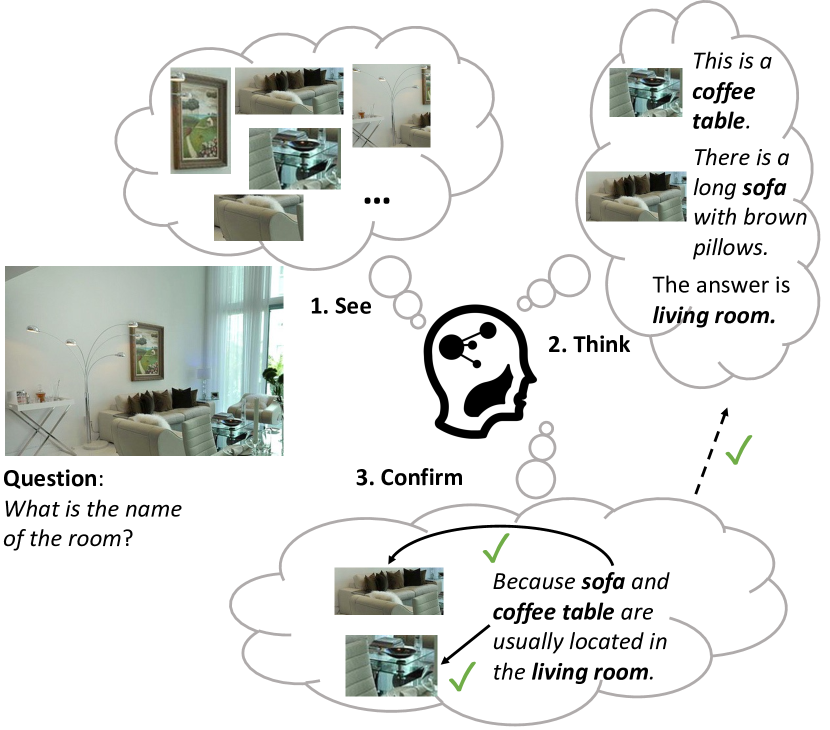
IPVRは、視覚概念を grounding し、LLM で推論し、合理性を検証して、知識ベースの視覚推論タスクを透明な段階的説明とともに解く対話的・反復 prompting フレームワークです。
Large pre-trained vision and language models have demonstrated remarkable capacities for various tasks. However, solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect the external world knowledge, and perform step-by-step reasoning to answer the questions correctly. To this end, we propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge-based visual reasoning. IPVR contains three stages, see, think and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend to the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer. The confirm stage further uses the LLM to generate the supporting rationale to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently. We conduct experiments on a range of knowledge-based visual reasoning datasets. We found our IPVR enjoys several benefits, 1). it achieves better performance than the previous few-shot learning baselines; 2). it enjoys the total transparency and trustworthiness of the whole reasoning process by providing rationales for each reasoning step; 3). it is computation-efficient compared with other fine-tuning baselines.
研究の動機と目的
- 画像理解と外部知識、段階的推論を組み合わせて知識ベースの視覚推論(KB-VQA)を解決する動機づけ。
- 概念を grounding し、文脈テキストを生成し、回答を反復的に refined するモジュラーな IPVR パイプライン(see–think–confirm)を提案。
- 合理性を提供し、合理性、画像内容、出力の整合性を検証することで透明性を高める。
- interpretability とモジュラリティを維持しつつ、全ファインチューニングより効率を向上させる。
提案手法
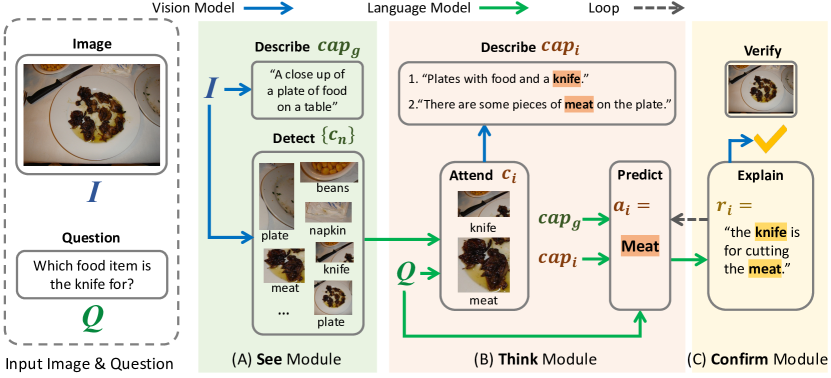
- See モジュールはシーンパーサーを用いて画像内の候補視覚概念を検出し、全体の画像キャプションを生成する。
- Think モジュールはインコンテキストプロンプティング済みの LLM を用いて重要概念に注意を払い、注目概念の地域キャプションを生成し、回答を予測する。
- Confirm モジュールは LLM に合理性を生成させ、クロスモダリティ分類器を用いて合理性と画像の整合性を検証した後、ループに戻す。
- 反復ループは consecutive な回答が収束するまで think と confirm を繰り返し、回答と合理性のトレースを生成する。
- 実装は物体概念に Faster-RCNN、地域キャプションに BLIP、LLM に OPT-66B、合理性と画像検証に CLIP を用いる。
実験結果
リサーチクエスチョン
- RQ1視覚と言語モデル間の対話的 prompting により、KB-VQA で少数ショット prompting でも高精度を達成できるか。
- RQ2反復的な think–confirm prompting が透明で検証可能な推論トレースを提供し、信頼性とパフォーマンスを向上させるか。
- RQ3各 IPVR コンポーネント(attend/describe、合理性生成、検証)がパフォーマンスと効率に与える影響はどの程度か。
- RQ4IPVR はKB-VQAベンチマークにおいて、学習を文脈内で行う基準法やファインチューニングベースのアプローチとどのように比較されるか。
主な発見
- IPVR は KB-VQA ベンチマーク(OK-VQA および A-OKVQA)で従来の少数ショット学習ベースラインより良い性能を示す。
- IPVR は視覚概念、地域キャプション、合理性を含む透明な、段階的な推論トレースを提供する。
- 合理性の生成と、それを跨着モダリティ分類器での検証が回答の正確性と一貫性を向上させる。
- IPVR は全ファインチューニングベースラインと比較して計算効率を保ちつつ、推論パイプラインを通じて解釈性を維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。