[論文レビュー] SEGA: Instructing Text-to-Image Models using Semantic Guidance
SEGA は、拡散ベースのテキストから画像へのモデルに対してセマンティック・ガイダンスを導入し、再訓練なしでゼロショット、アーキテクチャ非依存、複数概念の編集を、ノイズ推定空間の疎な次元を操作することによって実現します。
Text-to-image diffusion models have recently received a lot of interest for their astonishing ability to produce high-fidelity images from text only. However, achieving one-shot generation that aligns with the user's intent is nearly impossible, yet small changes to the input prompt often result in very different images. This leaves the user with little semantic control. To put the user in control, we show how to interact with the diffusion process to flexibly steer it along semantic directions. This semantic guidance (SEGA) generalizes to any generative architecture using classifier-free guidance. More importantly, it allows for subtle and extensive edits, changes in composition and style, as well as optimizing the overall artistic conception. We demonstrate SEGA's effectiveness on both latent and pixel-based diffusion models such as Stable Diffusion, Paella, and DeepFloyd-IF using a variety of tasks, thus providing strong evidence for its versatility, flexibility, and improvements over existing methods.
研究の動機と目的
- Semantic Guidance (SEGA) の拡散モデルにおける正式な定義と直感を提供する。
- セマンティック・ディレクションがノイズ推定空間内で頑健・単調で、ほぼ分離されていることを示す。
- アーキテクチャの変更や訓練なしに、微妙な編集、構成/スタイルの変更、および芸術的に導かれた概念操作をSEGAが実行できることを示す。
- SEGA を関連手法と比較し、複数の生成モデルに対して実用的な有用性を示す。
提案手法
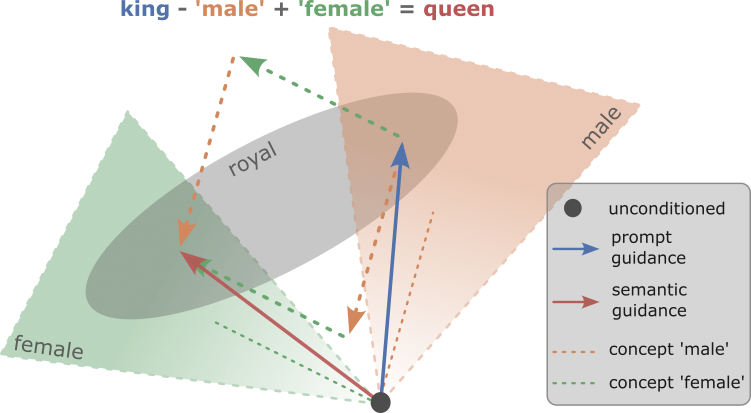
- 分類者なしガイダンスを拡張し、概念条件付きノイズ推定と無条件ノイズ推定から派生したセマンティック・ガイダンス計算を用いる。
- 概念プロンプトで条件付けられたイプシロン推定と無条件推定の差を分析してセマンティック・ディレクションを特定する。
- 概念ベクトルを形成するために、イプシロン次元のまばらな端部選択(lambda 百分位)を定義し、ほぼ孤立したままの表現を作る。
- ガイダンスをいつ、どう適用するかを制御し、安定した編集を加速するためのウォームアップ期間 delta とモーメンタム項を組み込む。
- 複数の概念を、個々の gamma_t ガイダンス項(gamma_i)を概念ごとのハイパパラメータで加重和して組み合わせることを許容する。
- 潜在モデルとピクセルベースの拡散モデルの両方に適用可能な実装に依存しない定式化を提供し、公開コード実装を含む。
実験結果
リサーチクエスチョン
- RQ1訓練やアーキテクチャの変更なしに、拡散モデルのノイズ推定空間からセマンティック・ディレクションを抽出できるか。
- RQ2セマンティック・ガイダンスベクトルは、プロンプトとドメインを跨って頑健性・独自性・単調性・分離性を示すか。
- RQ3SEGA は複数の編集を同時に、干渉なしで、制御可能な強さで実行できるか。
- RQ4編集の成功度と元の構成への忠実度の点で、SEGA は既存の拡散編集手法とどのように比較されるか。
- RQ5SEGA は不適切な概念からの生成を他のアーキテクチャに渡って緩和したり誘導できたりするか。
主な発見
- セマンティック・ガイダンス・ベクトルはノイズ推定から抽出可能で、単一のフォワードパスで適用できる。
- ガイダンス・ベクトルはドメインを跨って頑健で、概念ごとにほぼ一意であり、ガイダンス強度に対して効果が単調にスケールする。
- 異なる概念ベクトルはほぼ分離されており、干渉なしの同時編集を可能にし、マルチ概念操作を実現する。
- SEGA は複数の編集タスクで比較可能な手法より優れており、元の構成への忠実度を改善しつつスタイル転送やオブジェクトの除去を可能にする。
- 顔画像と I2P ベンチマークの実験では、SEGA は編集の高い成功率とアーキテクチャ横断での不適切な内容の強い緩和を達成する。
- 定性的およびユーザー調査の証拠は、SEGA の編集が忠実と認識され、多くのベースラインより望ましい結果を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。